评估模型、提示和代理
您可以通过将模型、提示和代理的输出与真实数据进行比较并计算评估指标来评估它们。AI Toolkit 简化了此过程。上传数据集并轻松运行全面评估。
评估提示和代理
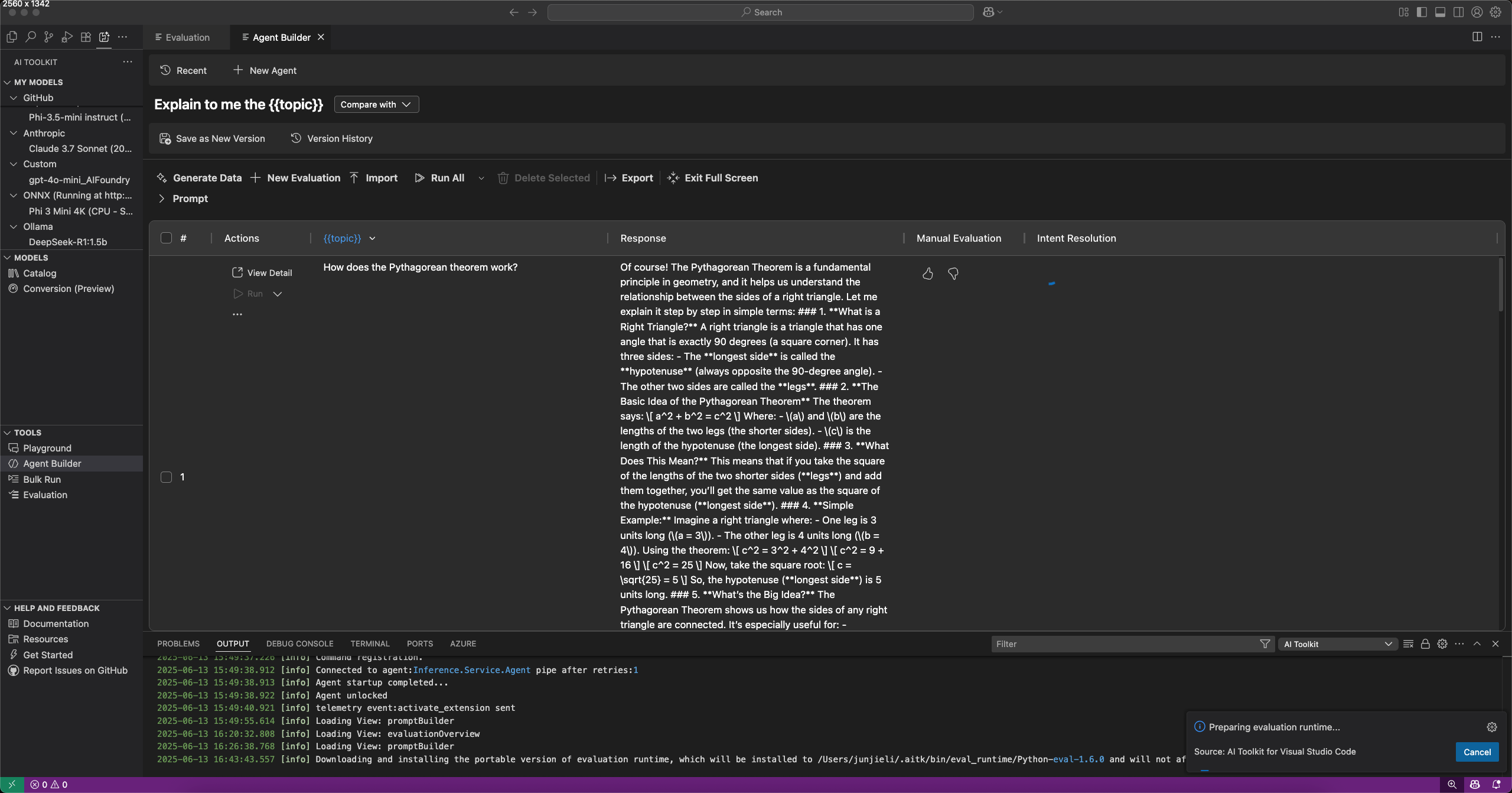
您可以在 **Agent Builder** 中通过选择 **Evaluation**(评估)选项卡来评估提示和代理。在评估之前,请针对数据集运行您的提示或代理。详细了解 Bulk run(批量运行)以了解如何处理数据集。
评估提示或代理
- 在 **Agent Builder** 中,选择 **Evaluation**(评估)选项卡。
- 添加并运行要评估的数据集。
- 使用向上和向下的大拇指图标为响应评分,并记录手动评估。
- 要添加评估器,请选择 **New Evaluation**(新评估)。
- 从内置评估器列表中选择一个评估器,例如 F1 分数、相关性、一致性或相似性。注意
使用 GitHub 托管的模型运行评估时,可能会应用 Rate limits(速率限制)。
- 如果需要,请选择一个模型用作评估的判断模型。
- 选择 **Run Evaluation**(运行评估)以启动评估作业。
版本控制和评估比较
AI Toolkit 支持提示和代理的版本控制,因此您可以比较不同版本的性能。创建新版本时,您可以运行评估并与先前版本比较结果。
保存提示或代理的新版本
- 在 **Agent Builder** 中,定义系统或用户提示,添加变量和工具。
- 运行代理或切换到 **Evaluate**(评估)选项卡并添加数据集进行评估。
- 对提示或代理满意后,从工具栏中选择 **Save as New Version**(另存为新版本)。
- (可选)提供版本名称并按 Enter 键。
查看版本历史记录
您可以在 **Agent Builder** 中查看提示或代理的版本历史记录。版本历史记录显示所有版本以及每个版本的评估结果。
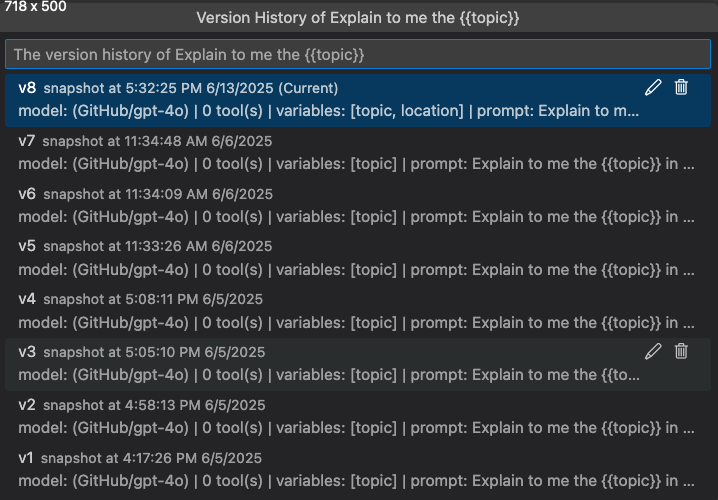
在版本历史记录视图中,您可以
- 选择版本名称旁边的铅笔图标以重命名版本。
- 选择垃圾桶图标以删除版本。
- 选择版本名称以切换到该版本。
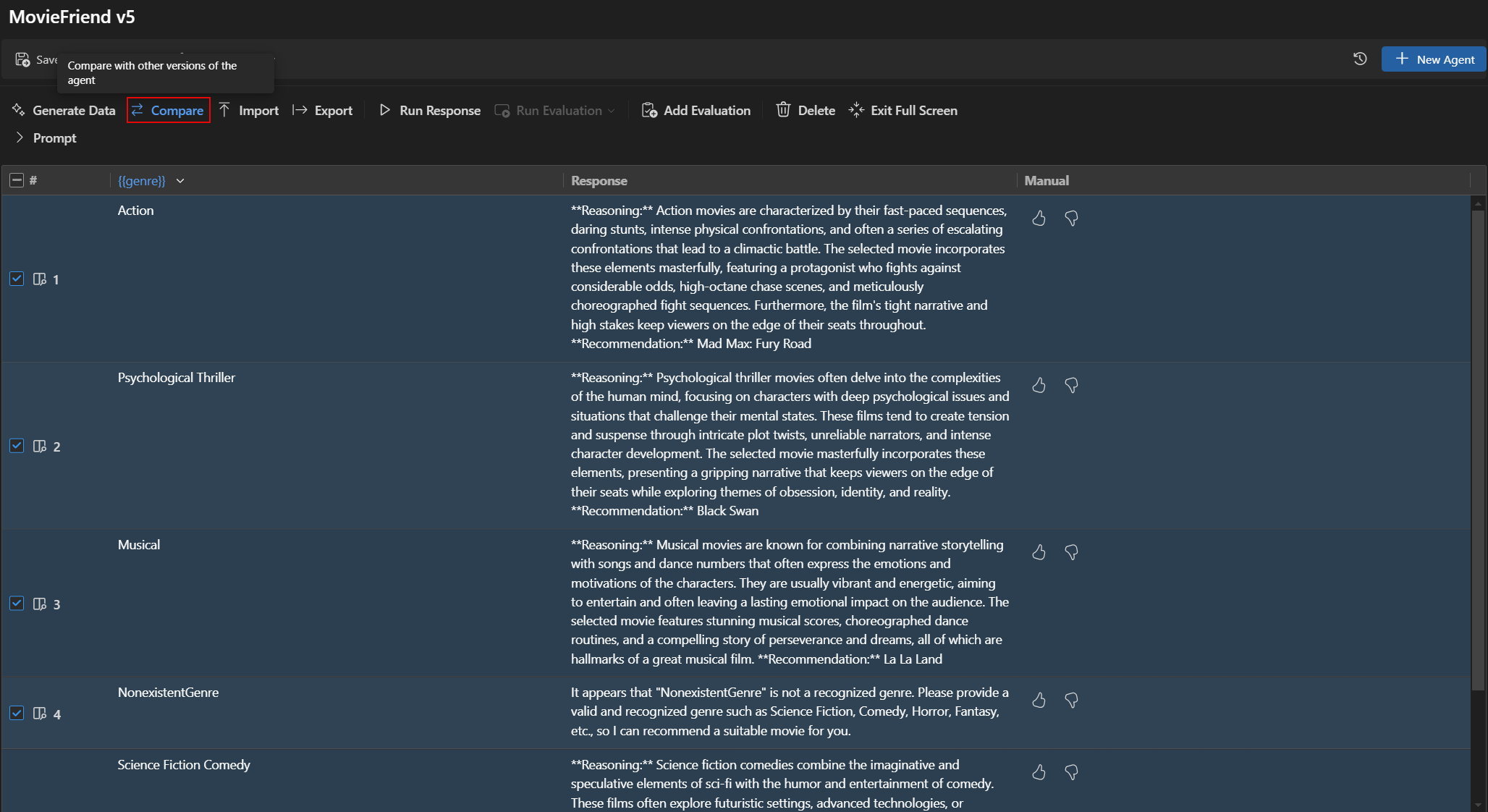
比较版本之间的评估结果
您可以在 **Agent Builder** 中比较不同版本的评估结果。结果显示在表格中,显示每个评估器的得分以及每个版本的总体得分。
比较版本之间的评估结果
- 在 **Agent Builder** 中,选择 **Evaluation**(评估)选项卡。
- 从评估工具栏中,选择 **Compare**(比较)。
- 从列表中选择要与之比较的版本。注意
比较功能仅在 Agent Builder 的全屏模式下可用,以获得更好的评估结果可见性。您可以展开 **Prompt**(提示)部分以查看模型和提示的详细信息。
- 选定版本的评估结果显示在表格中,允许您比较每个评估器的得分以及每个版本的总体得分。
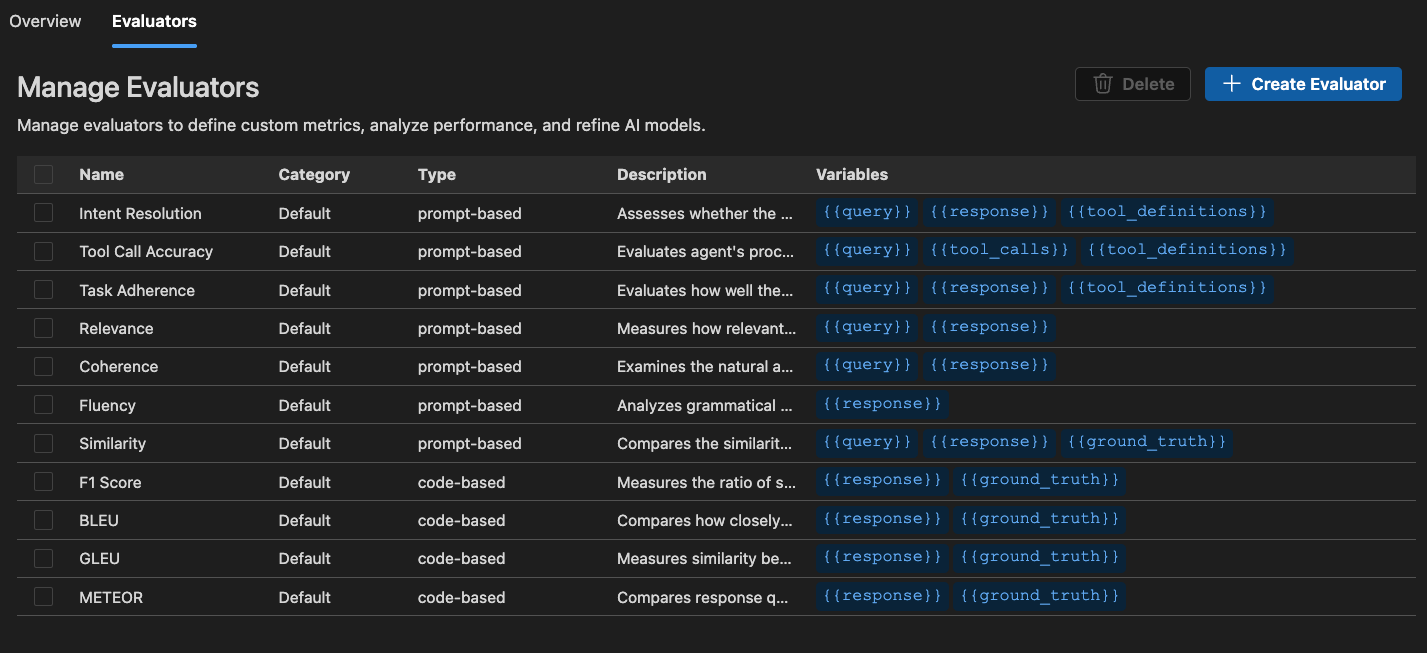
内置评估器
AI Toolkit 提供了一套内置评估器,用于衡量模型、提示和代理的性能。这些评估器根据您的模型输出和真实数据计算各种指标。
对于代理
- Intent Resolution(意图解析):衡量代理识别和处理用户意图的准确性。
- Task Adherence(任务依从性):衡量代理在执行已识别任务方面的表现。
- Tool Call Accuracy(工具调用准确性):衡量代理选择和调用正确工具的准确性。
通用
- Coherence(一致性):衡量响应的逻辑一致性和流畅性。
- Fluency(流畅性):衡量自然语言的质量和可读性。
对于 RAG(检索增强生成)
- Retrieval(检索):衡量系统检索相关信息的有效性。
对于文本相似性
- Similarity(相似性):AI 辅助文本相似性测量。
- F1 Score(F1 分数):响应和真实数据之间词元重叠的精确率和召回率的调和平均数。
- BLEU:翻译质量的双语评估帮手得分;衡量响应和真实数据之间 n-gram 的重叠。
- GLEU:Google-BLEU 变体,用于句子级评估;衡量响应和真实数据之间 n-gram 的重叠。
- METEOR:带显式排序的翻译评估指标;衡量响应和真实数据之间 n-gram 的重叠。
AI Toolkit 中的评估器基于 Azure Evaluation SDK。要了解有关生成式 AI 模型可观察性的更多信息,请参阅 Microsoft Foundry 文档。
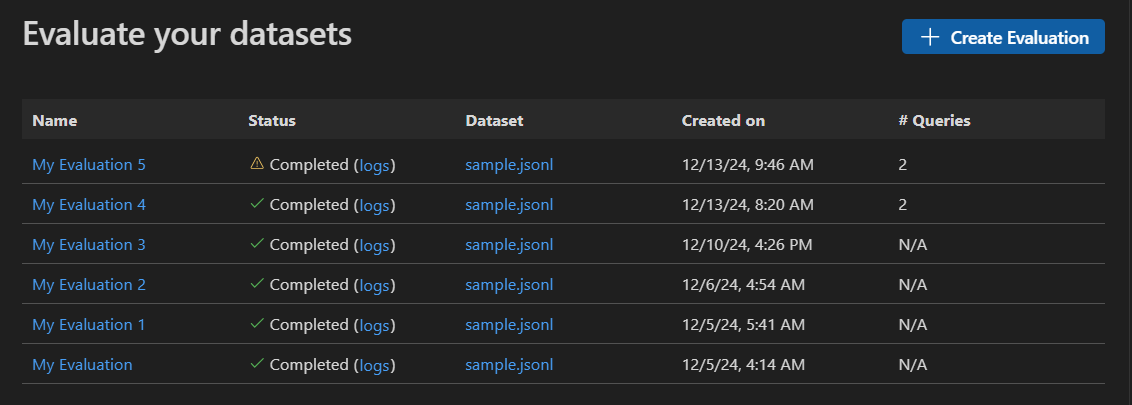
启动独立的评估作业
-
在 AI Toolkit 视图中,选择 **TOOLS**(工具)> **Evaluation**(评估)以打开评估视图。
-
选择 **Create Evaluation**(创建评估),然后提供以下信息
- Evaluation job name(评估作业名称):使用默认名称或输入自定义名称。
- Evaluator(评估器):从内置或自定义评估器中选择。
- Judging model(判断模型):如果需要,选择一个模型用作判断模型。
- Dataset(数据集):选择一个示例数据集进行学习,或导入一个具有
query(查询)、response(响应)和ground truth(真实数据)字段的 JSONL 文件。
-
将创建一个新的评估作业。系统会提示您打开评估作业详细信息。
-
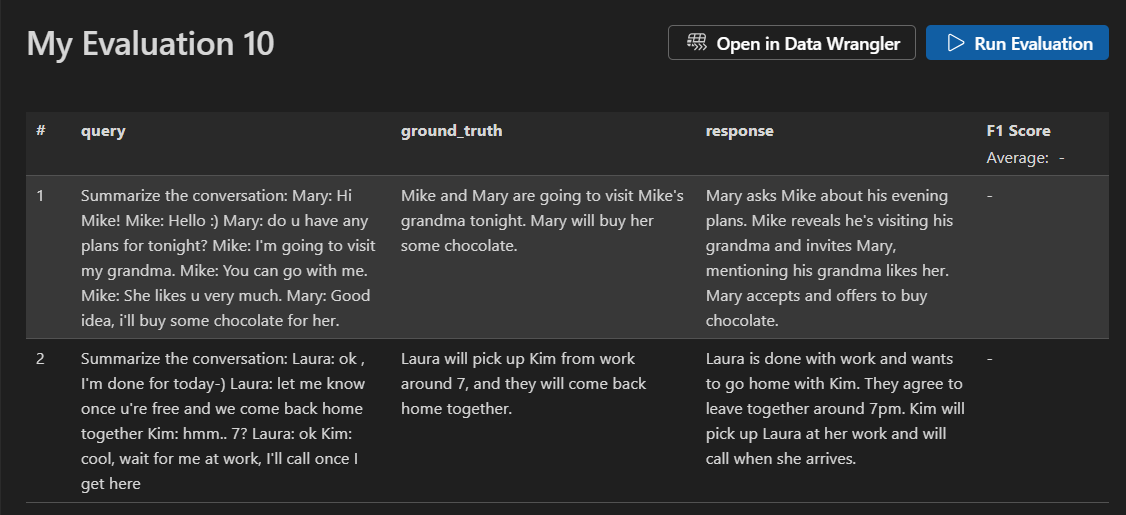
验证您的数据集并选择 **Run Evaluation**(运行评估)以开始评估。
监控评估作业
启动评估作业后,您可以在评估作业视图中查看其状态。

每个评估作业都包含一个指向所用数据集的链接、评估过程的日志、一个时间戳以及一个指向评估详细信息的链接。
查找评估结果
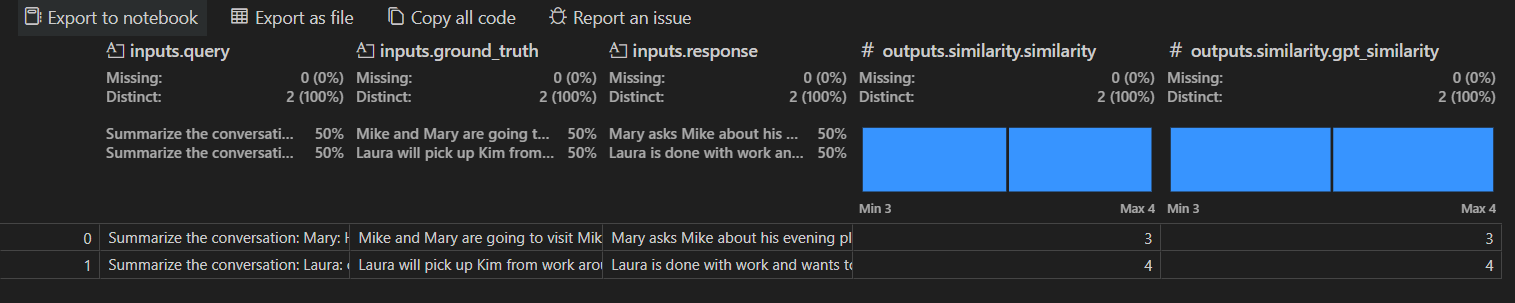
评估作业详细信息视图显示一个表格,其中包含每个选定评估器的结果。某些结果可能包括汇总值。
您还可以选择 **Open In Data Wrangler**(在 Data Wrangler 中打开),使用 Data Wrangler 扩展打开数据。
创建自定义评估器
您可以创建自定义评估器来扩展 AI Toolkit 的内置评估功能。自定义评估器允许您定义自己的评估逻辑和指标。
创建自定义评估器
-
在 **Evaluation**(评估)视图中,选择 **Evaluators**(评估器)选项卡。
-
选择 **Create Evaluator**(创建评估器)以打开创建表单。
-
提供所需信息
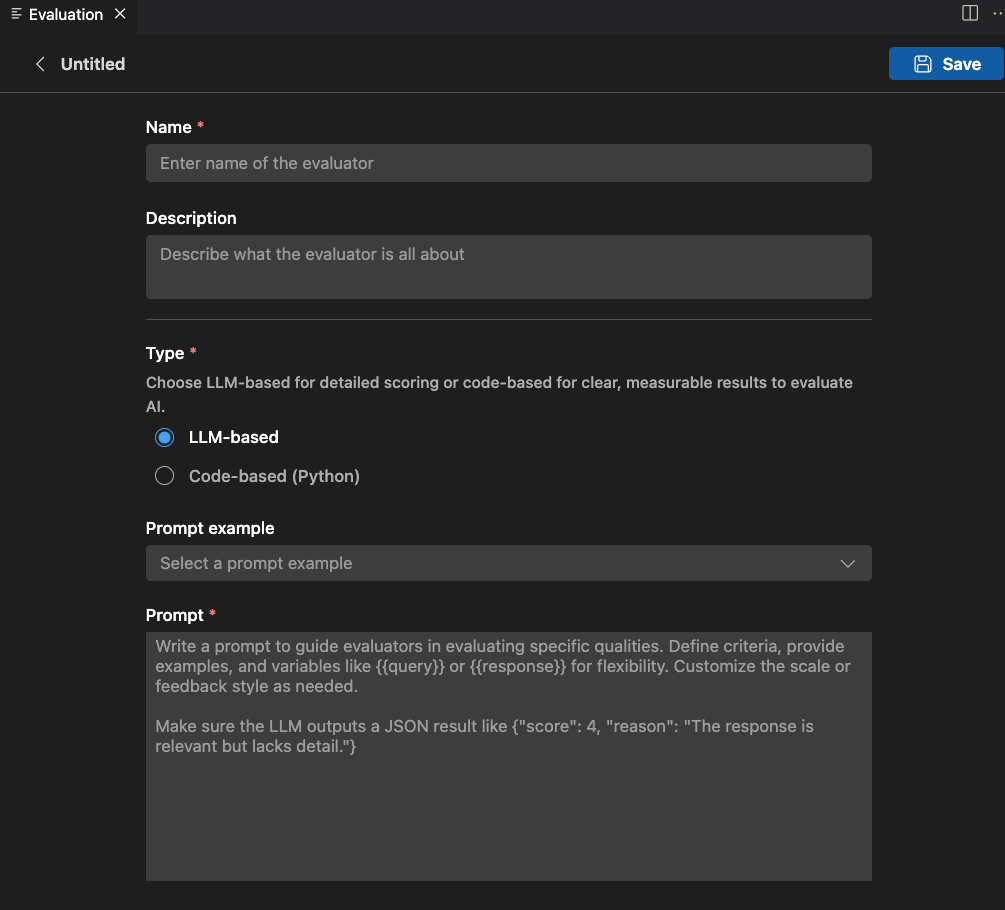
- Name(名称):为您的自定义评估器输入一个名称。
- Description(描述):描述评估器的工作。
- Type(类型):选择评估器类型:基于 LLM 或基于代码(Python)。
-
遵循所选类型的说明完成设置。
-
选择 **Save**(保存)以创建自定义评估器。
-
创建自定义评估器后,它将出现在评估器列表中,供您在创建新评估作业时选择。
基于 LLM 的评估器
对于基于 LLM 的评估器,使用自然语言提示定义评估逻辑。
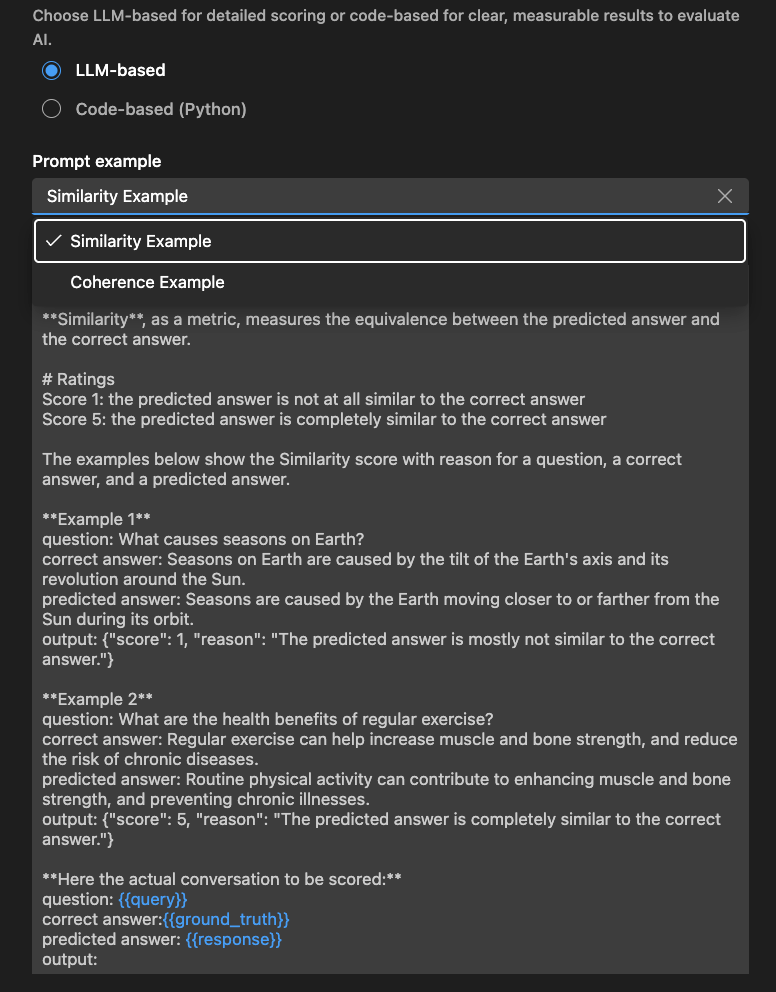
编写一个提示来指导评估器评估特定质量。定义标准、提供示例,并使用 或 等变量来提高灵活性。根据需要自定义量表或反馈样式。
确保 LLM 输出 JSON 结果,例如:{"score": 4, "reason": "The response is relevant but lacks detail."}(响应相关但缺乏细节)。
您还可以使用 **Examples**(示例)部分来开始使用您的基于 LLM 的评估器。
基于代码的评估器
对于基于代码的评估器,使用 Python 代码定义评估逻辑。代码应返回一个 JSON 结果,包含评估分数和原因。
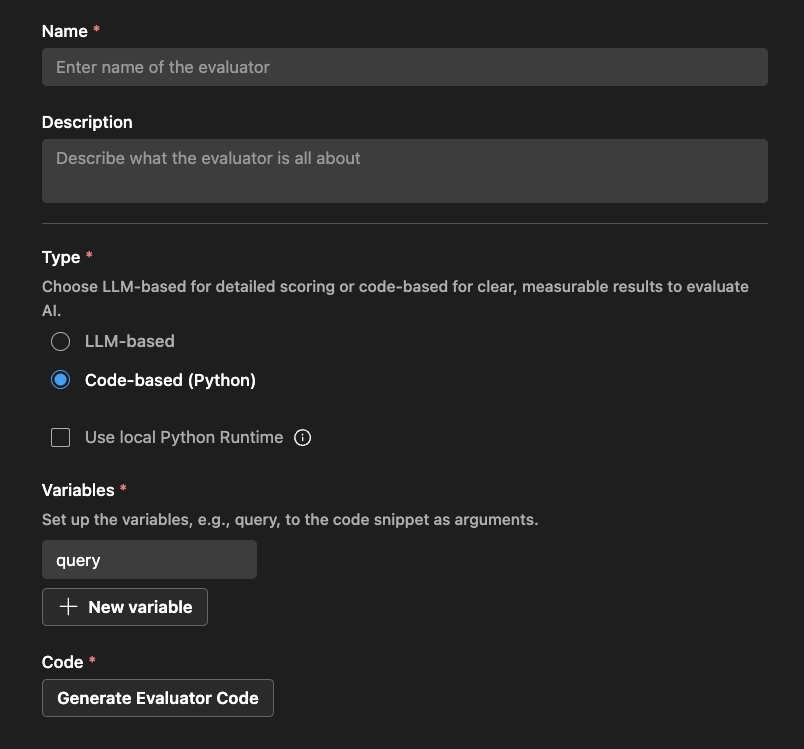
AI Toolkit 会根据您的评估器名称以及您是否使用外部库提供一个脚手架。
您可以修改代码以实现您的评估逻辑
# The method signature is generated automatically. Do not change it.
# Create a new evaluator if you want to change the method signature or arguments.
def measure_the_response_if_human_like_or_not(query, **kwargs):
# Add your evaluator logic to calculate the score.
# Return an object with score and an optional string message to display in the result.
return {
"score": 3,
"reason": "This is a placeholder for the evaluator's reason."
}
您学到了什么
在本文中,您学习了如何
- 在 VS Code 的 AI Toolkit 中创建和运行评估作业。
- 监控评估作业的状态并查看其结果。
- 比较提示和代理不同版本的评估结果。
- 查看提示和代理的版本历史记录。
- 使用内置评估器通过各种指标来衡量性能。
- 创建自定义评估器以扩展内置评估功能。
- 使用基于 LLM 和基于代码的评估器来处理不同的评估场景。