VS Code 中 Data Wrangler 快速入门指南
Data Wrangler 是一个以代码为中心的 VS Code 和 VS Code Jupyter Notebook 集成的数据查看和清理工具。它提供了一个丰富的用户界面来查看和分析您的数据,展示有见地的列统计信息和可视化,并在您清理和转换数据时自动生成 Pandas 代码。
以下是从 Notebook 中打开 Data Wrangler 来分析和清理数据的示例,然后将自动生成的代码导出回 Notebook。
本页的目的是帮助您快速上手并开始使用 Data Wrangler。
设置您的环境
- 如果您还没有安装 Python,请先安装 (注意: Data Wrangler 仅支持 Python 3.8 或更高版本)。
- 安装 Data Wrangler 扩展
当您第一次启动 Data Wrangler 时,它会询问您要连接到哪个 Python 内核。它还会检查您的机器和环境,以查看是否安装了所需的 Python 包,例如 Pandas。
打开 Data Wrangler
无论何时您在 Data Wrangler 中,都处于一个沙盒环境中,这意味着您可以安全地探索和转换数据。在您明确导出更改之前,原始数据集不会被修改。
从 Jupyter Notebook 启动 Data Wrangler
如果您在 Notebook 中有一个 Pandas DataFrame,在运行 df.head()、df.tail()、display(df)、print(df) 和 df 中的任何一个后,您将在单元格底部看到一个打开 'df' 到 Data Wrangler 按钮 (其中 df 是您的 DataFrame 的变量名)。
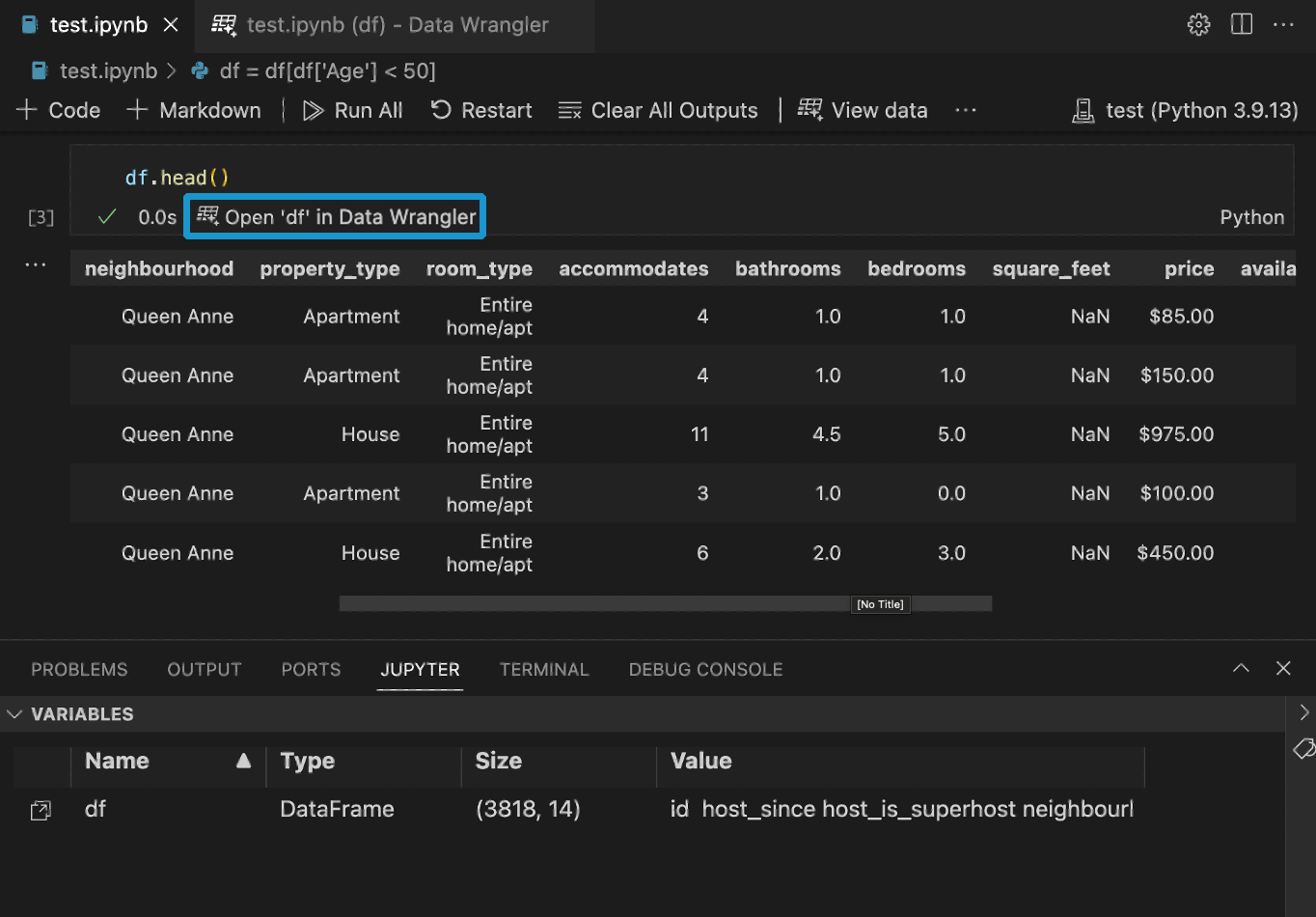
直接从文件启动 Data Wrangler
您也可以直接从本地文件 (如 .csv) 启动 Data Wrangler。要做到这一点,在 VS Code 中打开包含您想要打开的文件所在的任何文件夹。在文件资源管理器视图中,右键单击该文件,然后单击在 Data Wrangler 中打开。
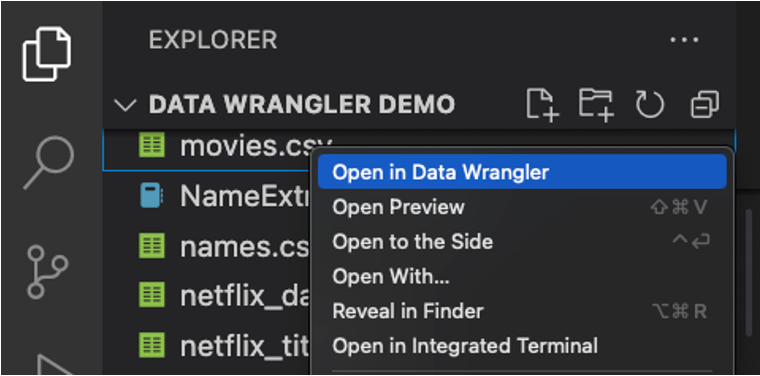
UI 导览
Data Wrangler 在处理您的数据时有两种模式。每种模式的详细信息将在下面的后续部分中进行解释。
- 查看模式: 查看模式优化了界面,以便您快速查看、过滤和排序数据。此模式非常适合对数据集进行初步探索。
- 编辑模式: 编辑模式优化了界面,以便您对数据集应用转换、清理或修改。当您在界面中应用这些转换时,Data Wrangler 会自动生成相关的 Pandas 代码,这些代码可以导出回您的 Notebook 以便重复使用。
注意:默认情况下,Data Wrangler 以查看模式打开。您可以在设置编辑器中更改此行为 。
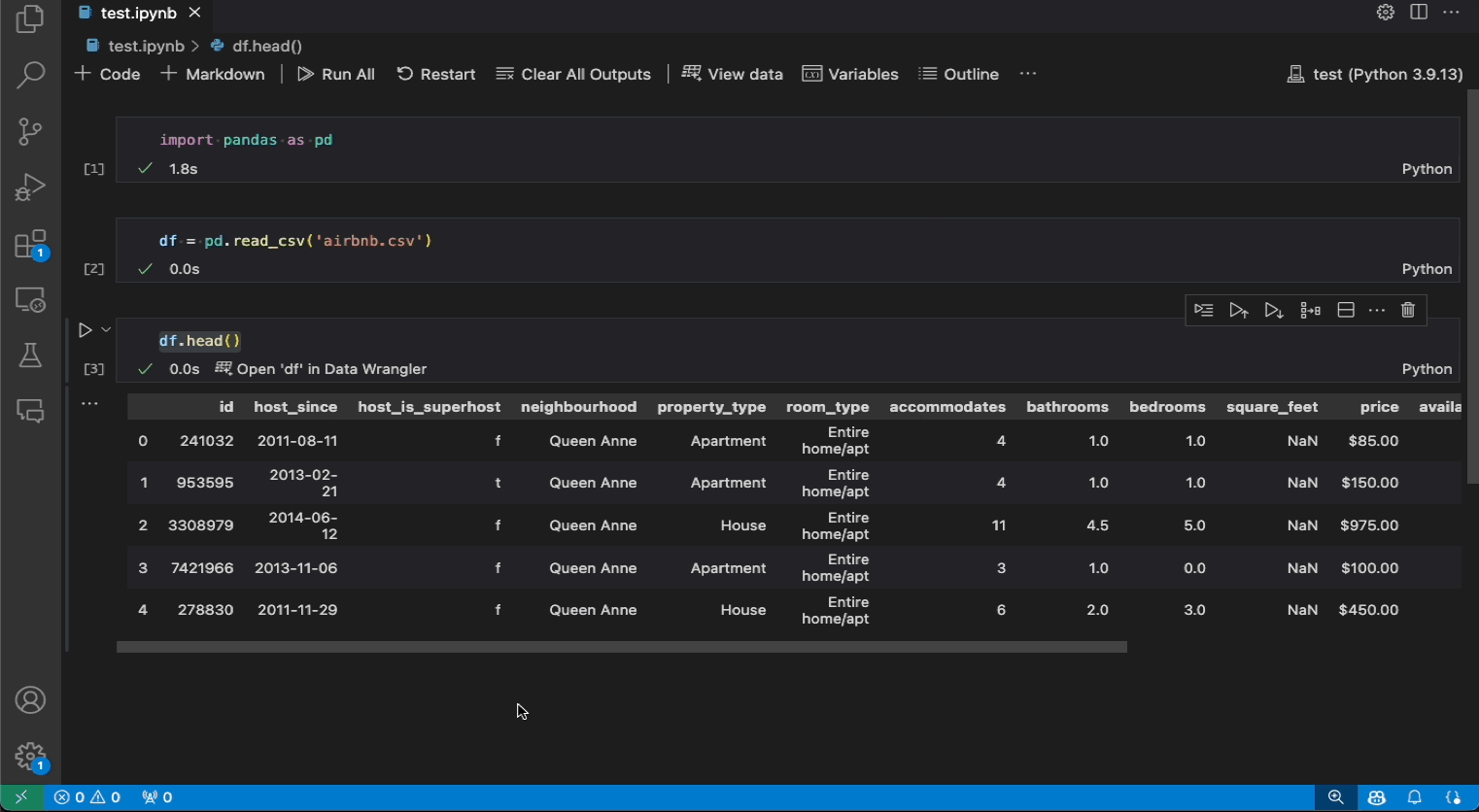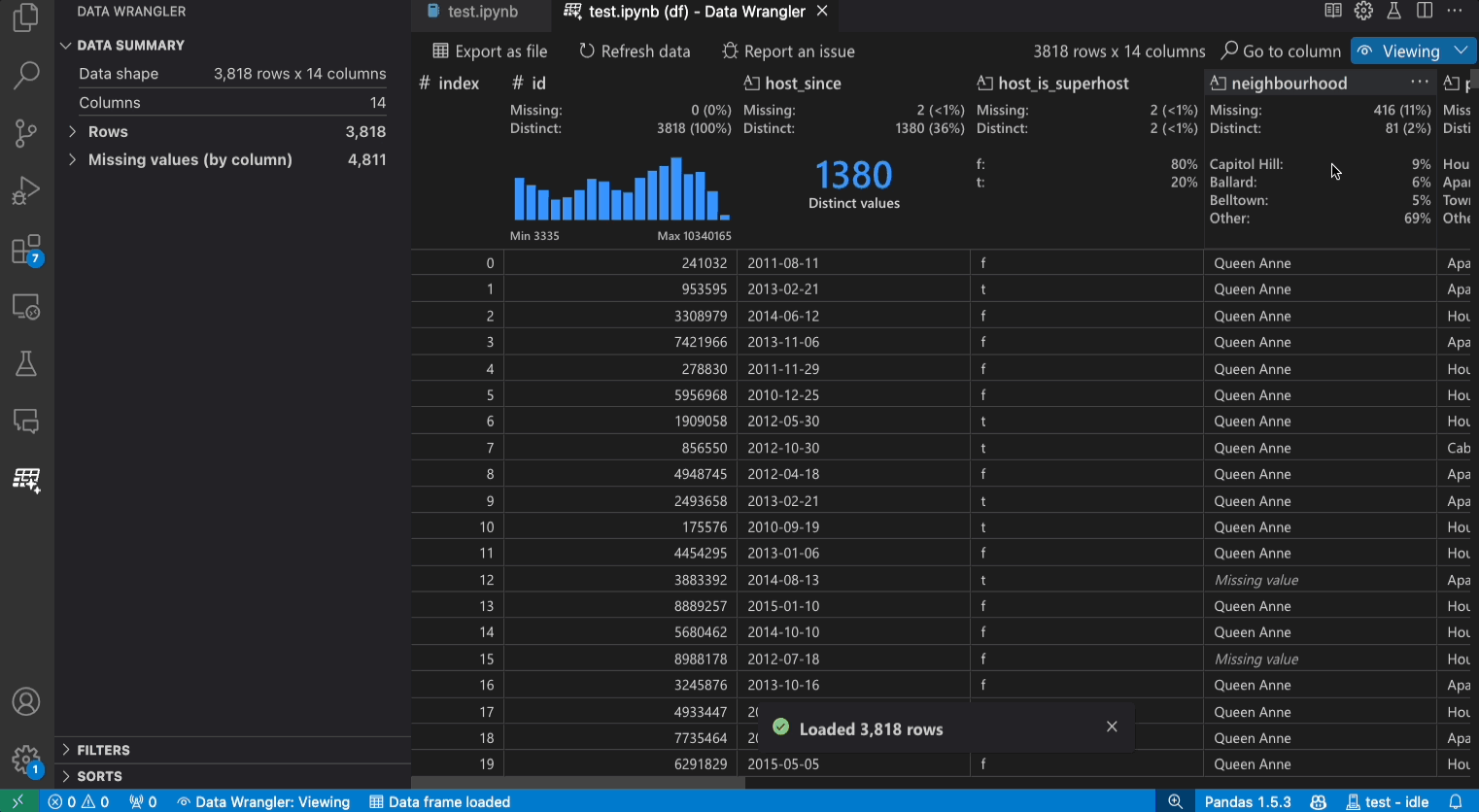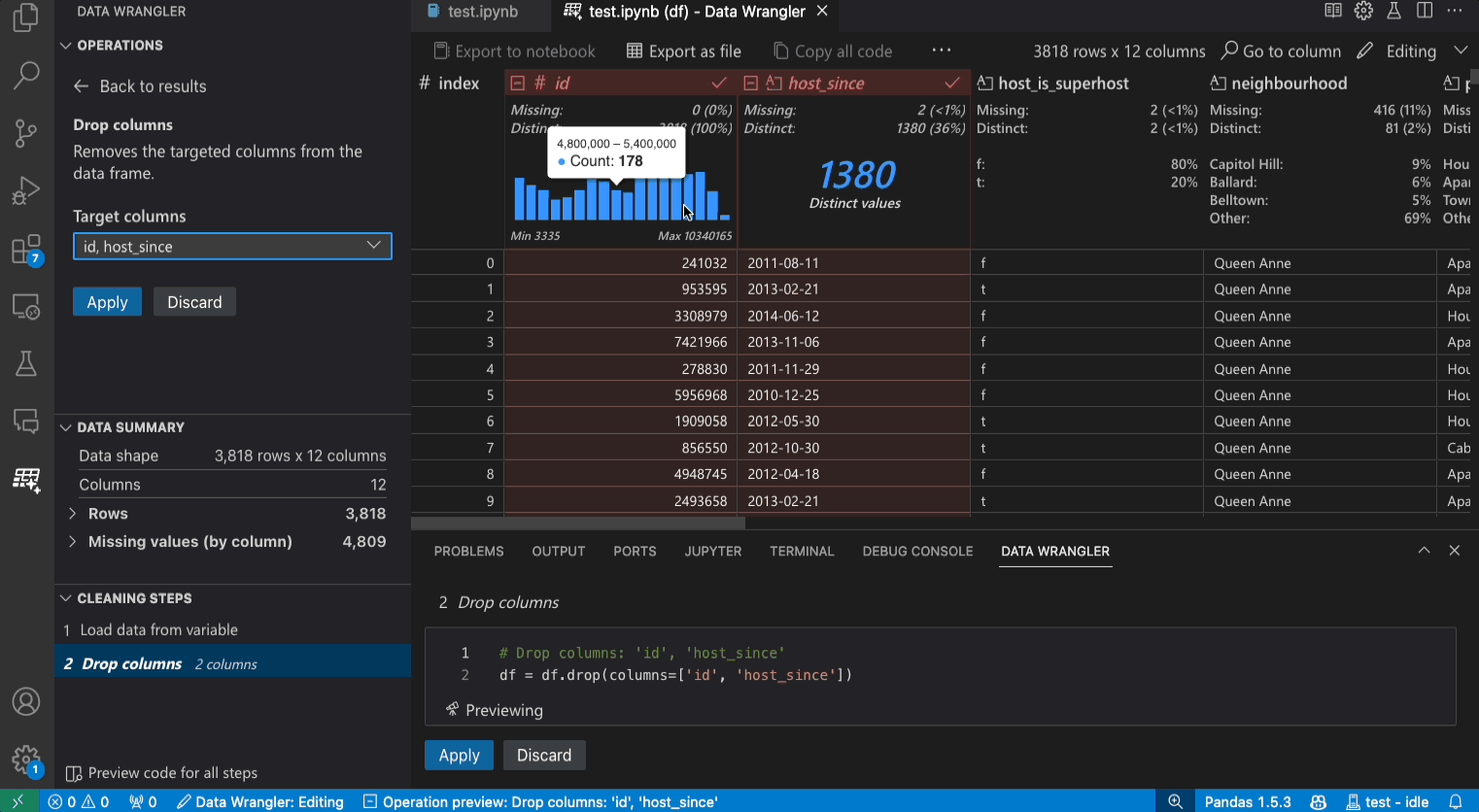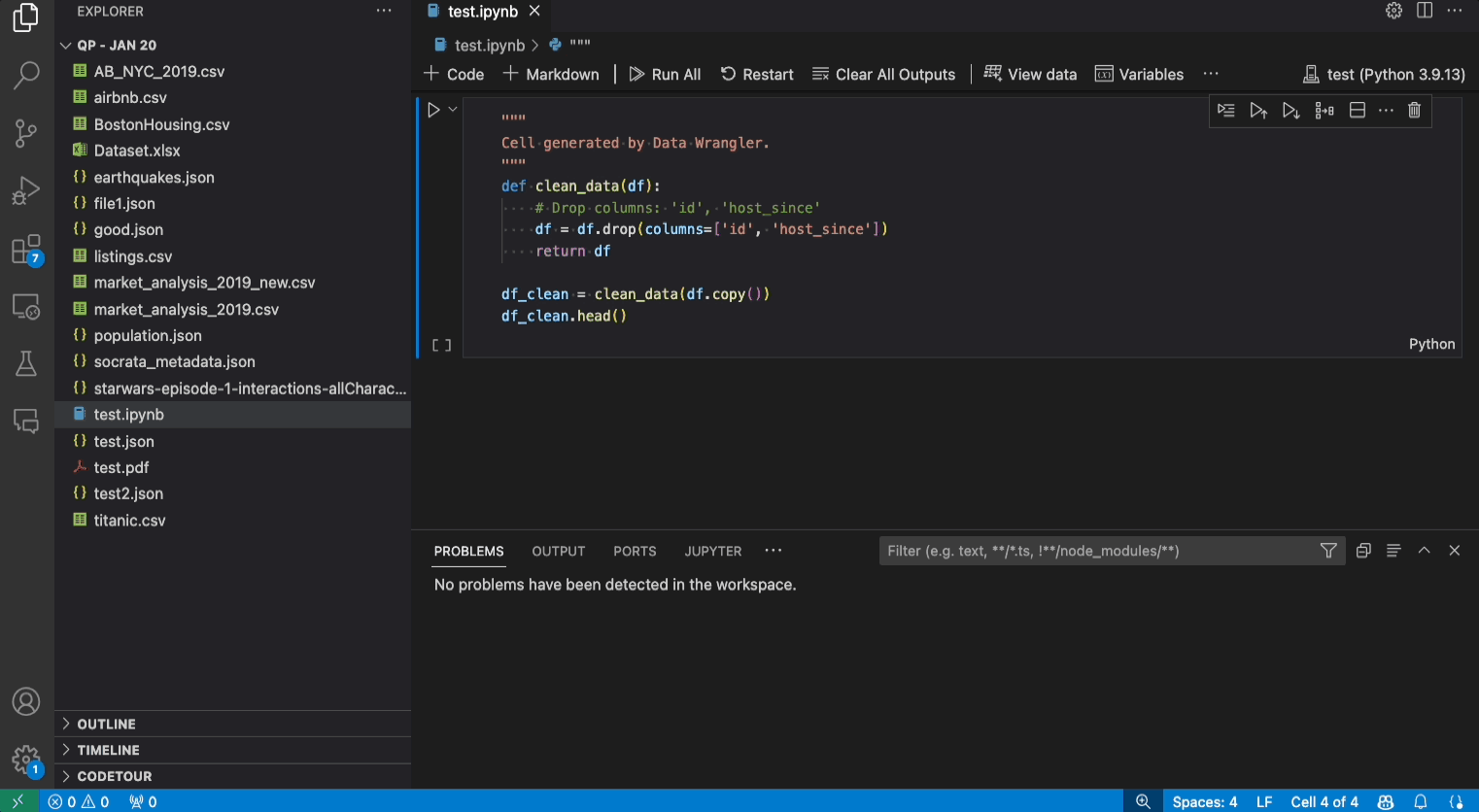
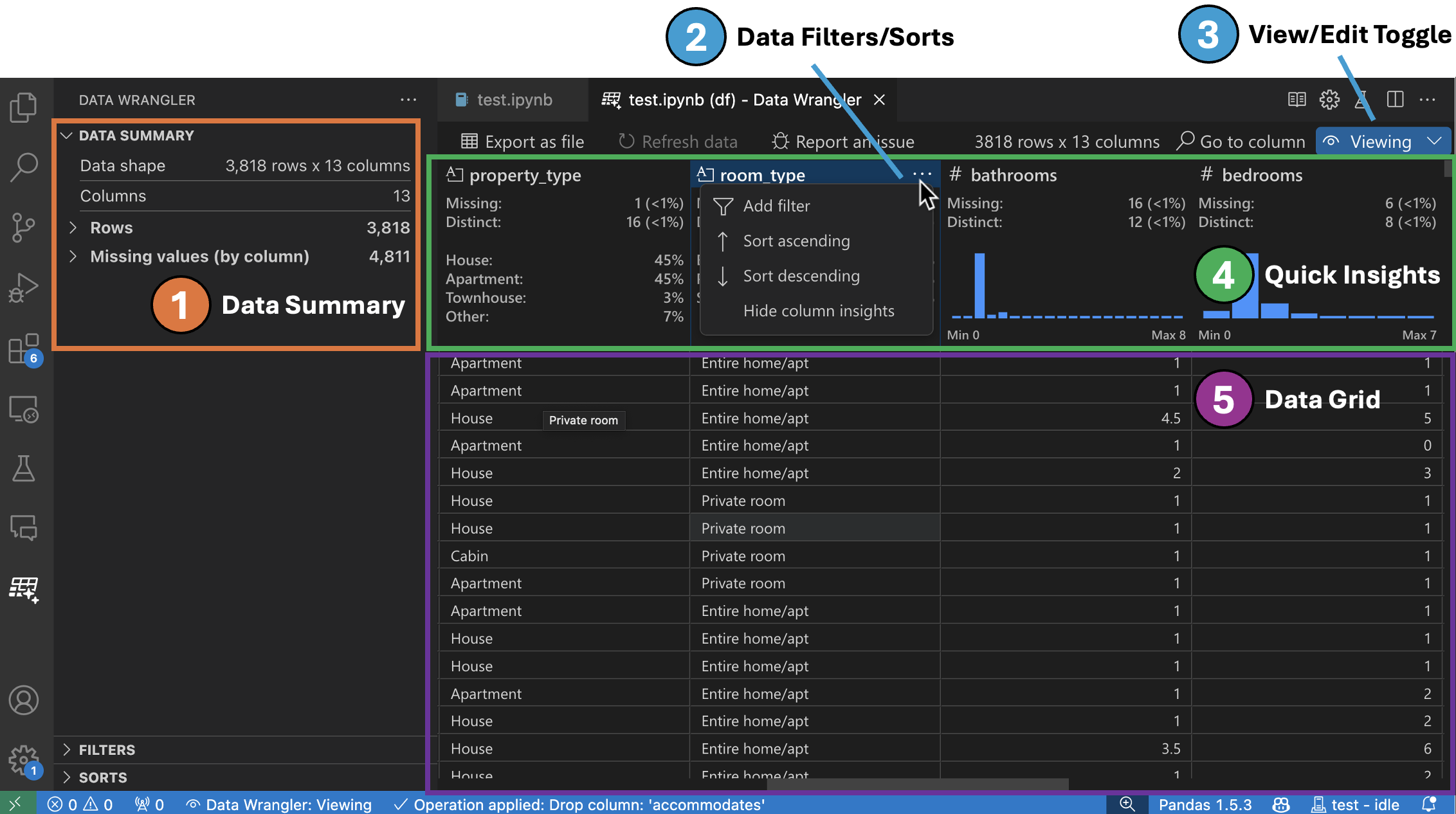
查看模式界面
-
数据摘要面板显示您整个数据集或特定列 (如果已选择) 的详细摘要统计信息。
-
您可以从列的表头菜单中对列应用任何数据过滤器/排序。
-
在 Data Wrangler 的查看或编辑模式之间切换,以访问内置的数据操作。
-
快速洞察标题是您可以在其中快速查看每列有价值信息的地方。根据列的数据类型,快速洞察会显示数据的分布或数据点的频率,以及缺失值和唯一值。
-
数据网格为您提供了一个可滚动的窗格,您可以在其中查看整个数据集。
编辑模式界面
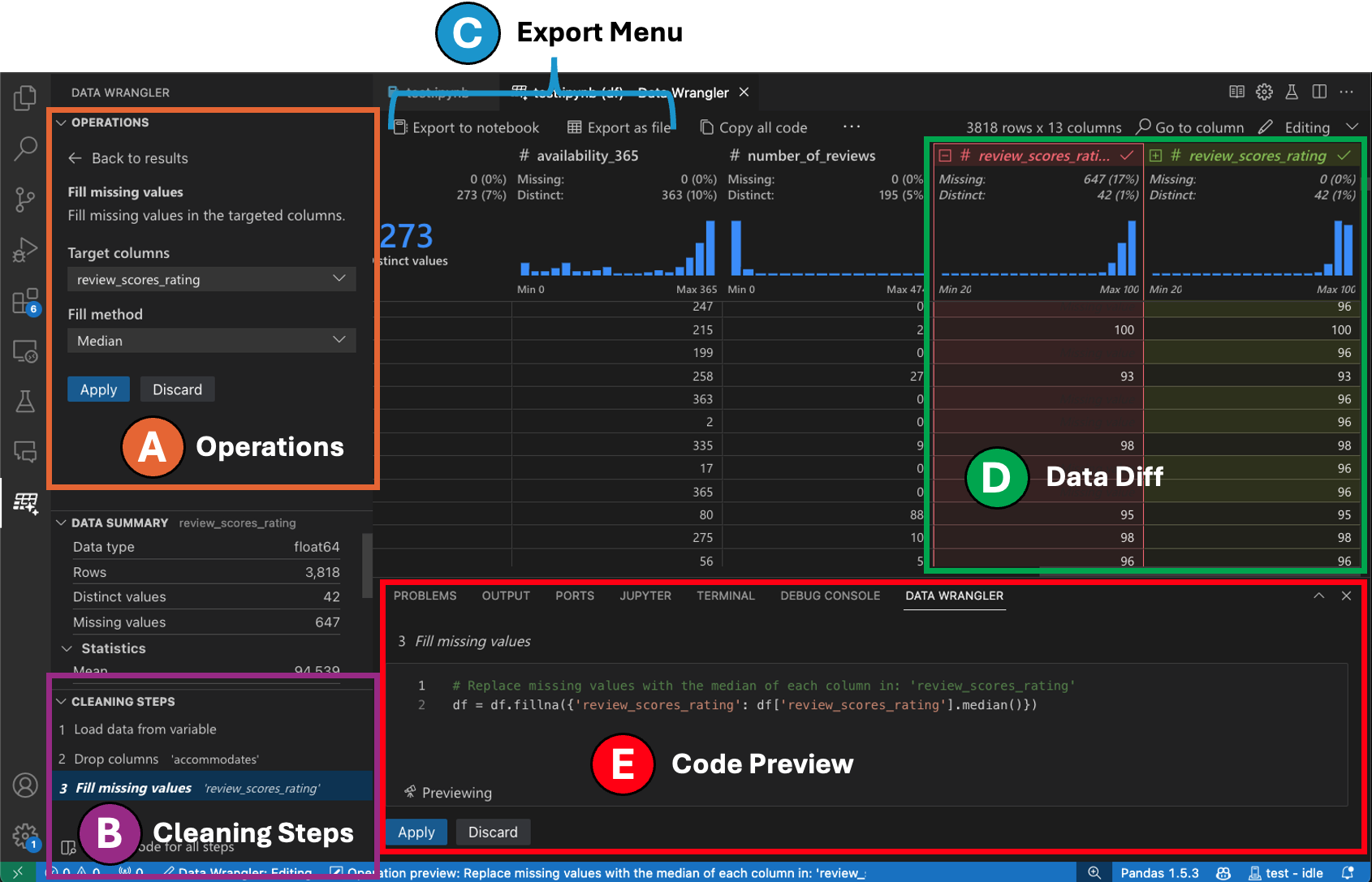
切换到编辑模式可以在 Data Wrangler 中启用其他功能和用户界面元素。在以下截图中,我们使用 Data Wrangler 将最后一列中的缺失值替换为该列的中位数。
-
操作面板是您可以搜索 Data Wrangler 所有内置数据操作的地方。操作按类别组织。
-
清理步骤面板显示了先前应用的所有操作的列表。它使用户能够撤销特定的操作或编辑最新的操作。选择一个步骤将突出显示数据网格中的更改,并显示与该操作相关的生成代码。
-
导出菜单允许您将代码导出回 Jupyter Notebook 或将数据导出到新文件。
-
当您选择了一个操作并预览其对数据的影响时,数据网格会叠加显示您对数据所做更改的数据差异视图。
-
代码预览部分显示当选择一个操作时 Data Wrangler 生成的 Python 和 Pandas 代码。当没有选择操作时,它保持为空。您可以编辑生成的代码,这将导致数据网格突出显示对数据的影响。
示例:替换数据集中的缺失值
给定一个数据集,一个常见的数据清理任务是处理数据中存在的任何缺失值。下面的示例展示了如何使用 Data Wrangler 将列中的缺失值替换为该列的中位数。虽然转换是通过界面完成的,但 Data Wrangler 也会自动生成替换缺失值所需的 Python 和 Pandas 代码。
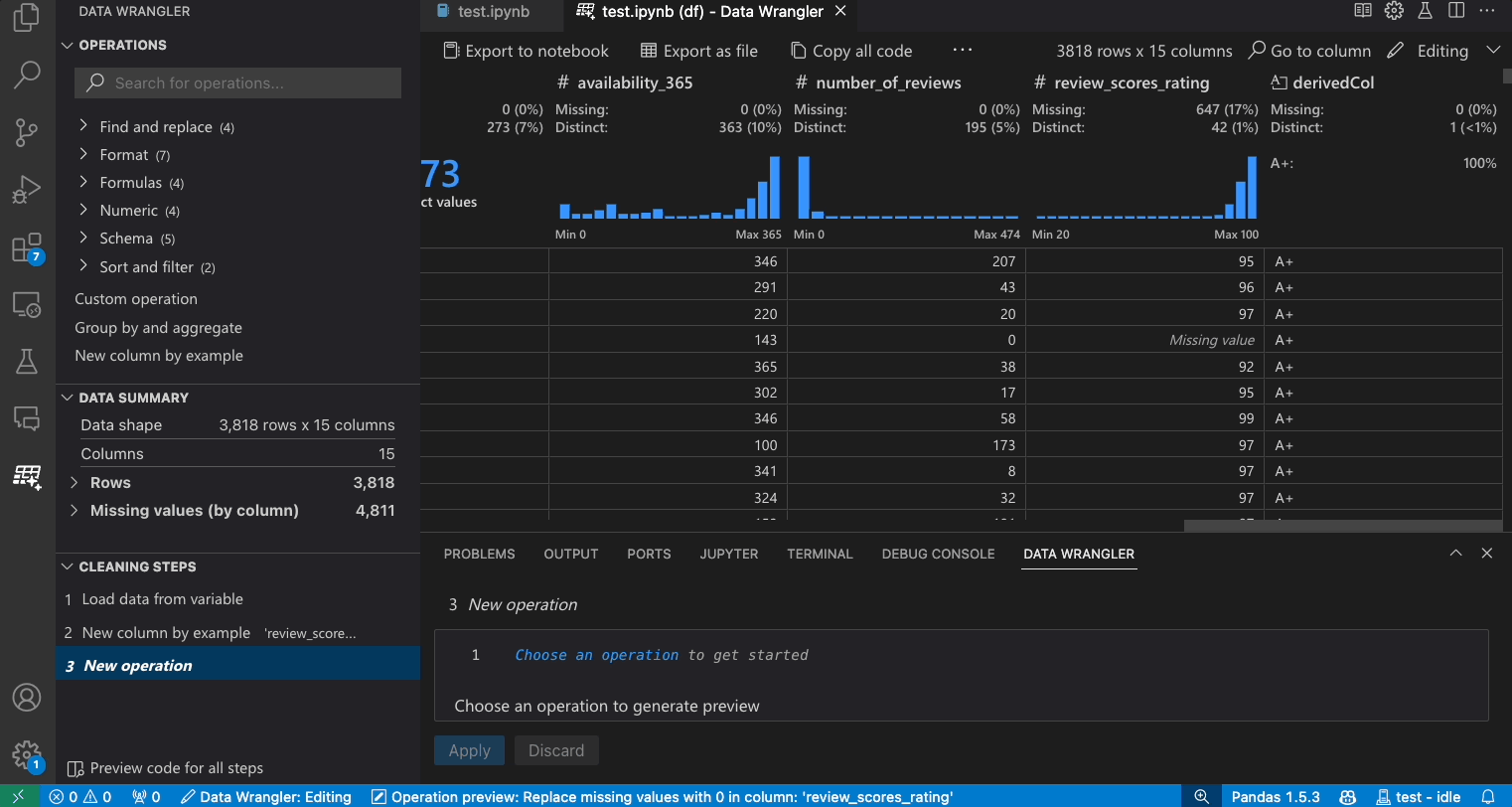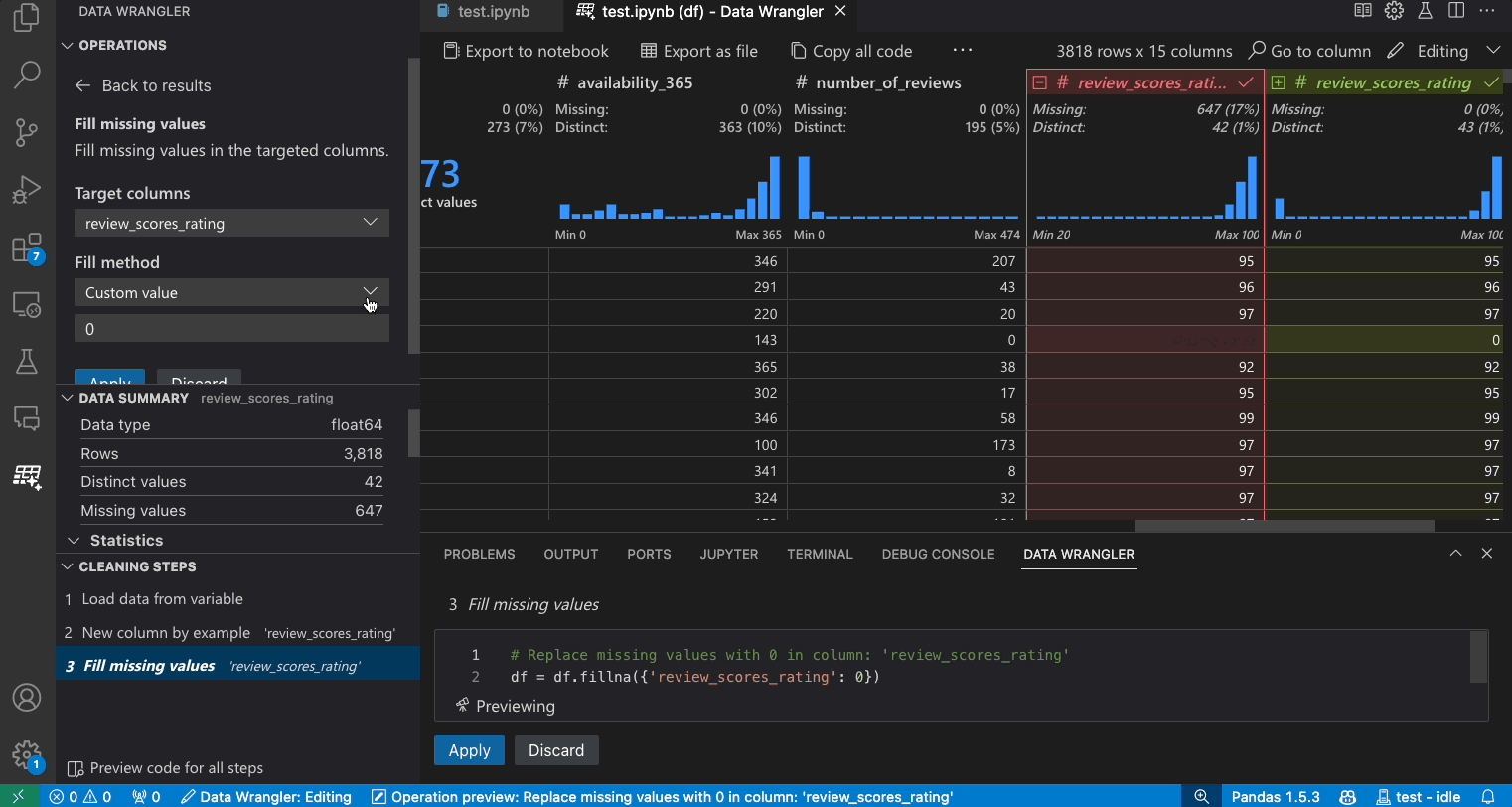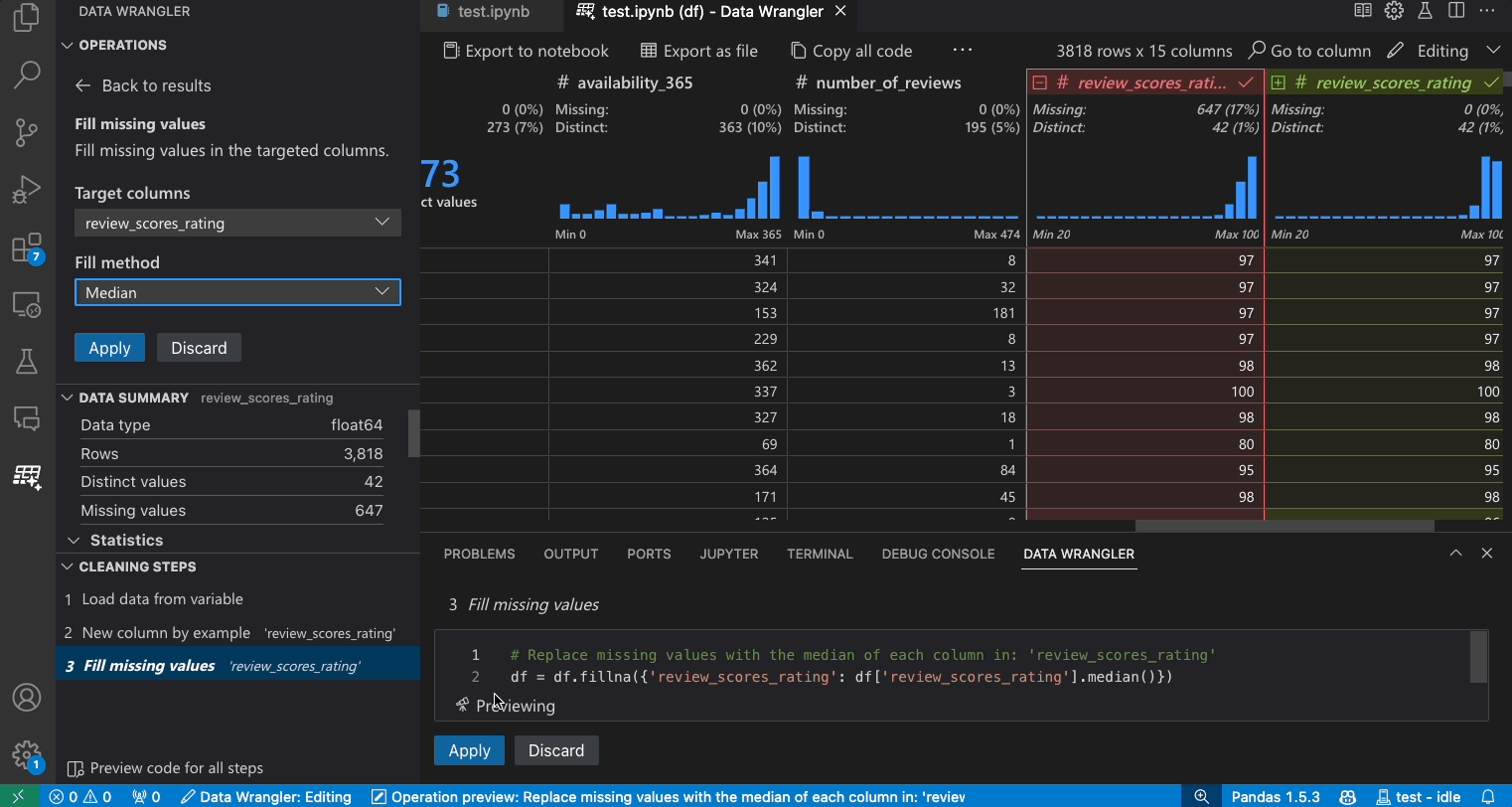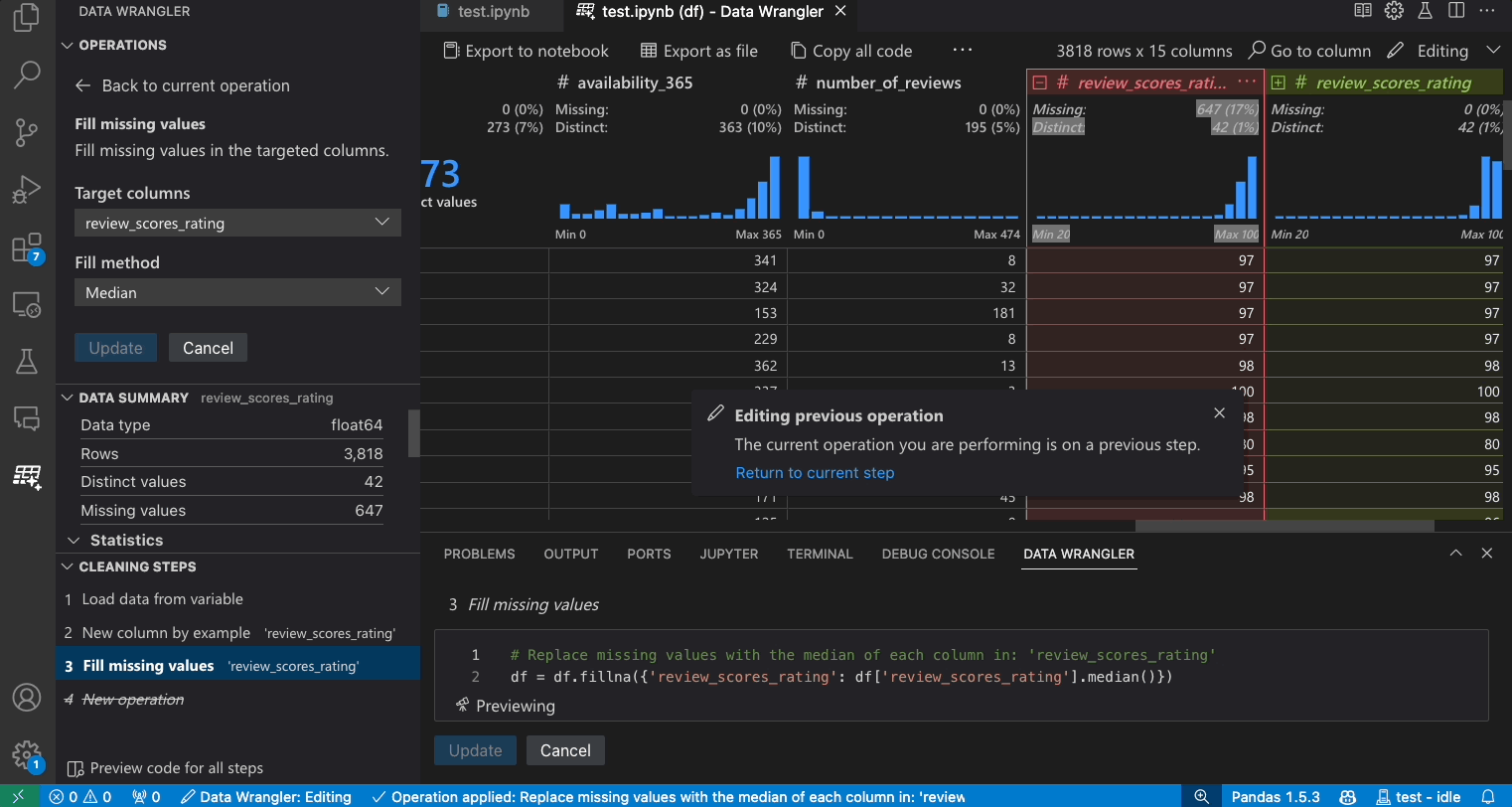
- 在操作面板中,搜索填充缺失值操作。
- 在参数中指定您想要用什么来替换缺失值。在这种情况下,我们将用该列的中位数来替换缺失值。
- 验证数据网格是否向您显示了数据差异中的正确更改。
- 验证 Data Wrangler 生成的代码是否符合您的预期。
- 应用该操作,它将被添加到您的清理步骤历史记录中。
后续步骤
本页介绍了如何快速开始使用 Data Wrangler。有关 Data Wrangler 的完整文档和教程,包括 Data Wrangler 目前支持的所有内置操作,请参阅以下页面。