VS Code 中的数据科学教程
本教程演示了如何使用 Visual Studio Code 和 Microsoft Python 扩展以及常见的数据科学库来探索基本的数据科学场景。具体来说,您将使用泰坦尼克号的乘客数据,学习如何设置数据科学环境、导入和清理数据、创建用于预测泰坦尼克号上生存情况的机器学习模型,以及评估生成模型的准确性。
先决条件
完成本教程需要进行以下安装。如果尚未安装,请确保进行安装。
-
从 Visual Studio Marketplace 安装 VS Code 的 Python 扩展 和 VS Code 的 Jupyter 扩展。有关安装扩展的更多详细信息,请参阅 扩展市场。这两个扩展都由 Microsoft 发布。
-
注意:如果您已安装完整的 Anaconda 发行版,则无需安装 Miniconda。或者,如果您不想使用 Anaconda 或 Miniconda,可以创建一个 Python 虚拟环境,并使用 pip 安装本教程所需的包。如果您选择此路径,则需要安装以下包:pandas、jupyter、seaborn、scikit-learn、keras 和 tensorflow。
设置数据科学环境
Visual Studio Code 和 Python 扩展为数据科学场景提供了出色的编辑器。借助对 Jupyter 笔记本的本机支持以及 Anaconda,可以轻松入门。在本节中,您将为本教程创建一个工作区,创建一个包含本教程所需数据科学模块的 Anaconda 环境,并创建一个 Jupyter 笔记本,您将使用它来创建机器学习模型。
-
首先,为数据科学教程创建一个 Anaconda 环境。打开 Anaconda 命令提示符,然后运行
conda create -n myenv python=3.10 pandas jupyter seaborn scikit-learn keras tensorflow来创建一个名为 myenv 的环境。有关创建和管理 Anaconda 环境的更多信息,请参阅 Anaconda 文档。 -
接下来,在方便的位置创建一个文件夹,作为本教程的 VS Code 工作区,将其命名为
hello_ds。 -
通过运行 VS Code 并使用 文件 > 打开文件夹 命令,在 VS Code 中打开项目文件夹。由于您创建了该文件夹,因此可以安全地信任打开文件夹。
-
VS Code 启动后,创建将用于本教程的 Jupyter 笔记本。打开命令面板(⇧⌘P (Windows、Linux Ctrl+Shift+P)),然后选择 创建:新的 Jupyter 笔记本。

注意:或者,您也可以从 VS Code 文件资源管理器中使用新建文件图标创建一个名为
hello.ipynb的笔记本文件。 -
使用 文件 > 另存为... 将文件另存为
hello.ipynb。 -
文件创建后,您应该会在笔记本编辑器中看到已打开的 Jupyter 笔记本。有关本机 Jupyter 笔记本支持的更多信息,您可以阅读 Jupyter Notebooks 主题。
-
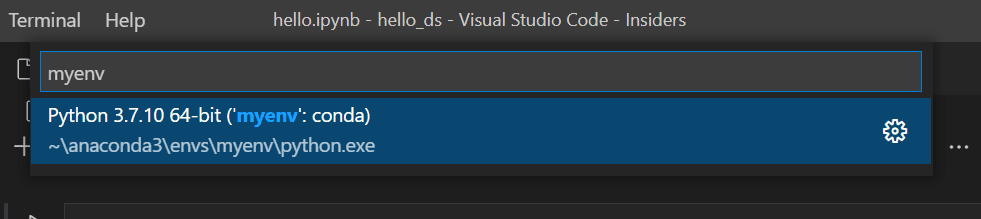
现在,在笔记本的右上角选择 选择内核。

-
选择上面创建的 Python 环境来运行您的内核。
-
要从 VS Code 的集成终端管理您的环境,请使用 (⌃` (Windows、Linux Ctrl+`)) 打开它。如果您的环境未激活,您可以在终端中像平常一样激活它(
conda activate myenv)。
准备数据
本教程使用 泰坦尼克号数据集,该数据集可在 OpenML.org 上获取,该数据集来自范德堡大学生物统计学系,位于 https://hbiostat.org/data。泰坦尼克号数据提供了关于泰坦尼克号乘客生存情况以及乘客特征(如年龄和船票等级)的信息。利用这些数据,本教程将建立一个模型来预测给定乘客是否会在泰坦尼克号沉没中幸存下来。本节演示了如何在 Jupyter 笔记本中加载和操作数据。
-
首先,从 hbiostat.org 下载泰坦尼克号数据,保存为 CSV 文件(右上角有下载链接),命名为
titanic3.csv,并将其保存到上节中创建的hello_ds文件夹。 -
如果您尚未在 VS Code 中打开该文件,请转到 文件 > 打开文件夹,然后打开
hello_ds文件夹和 Jupyter 笔记本(hello.ipynb)。 -
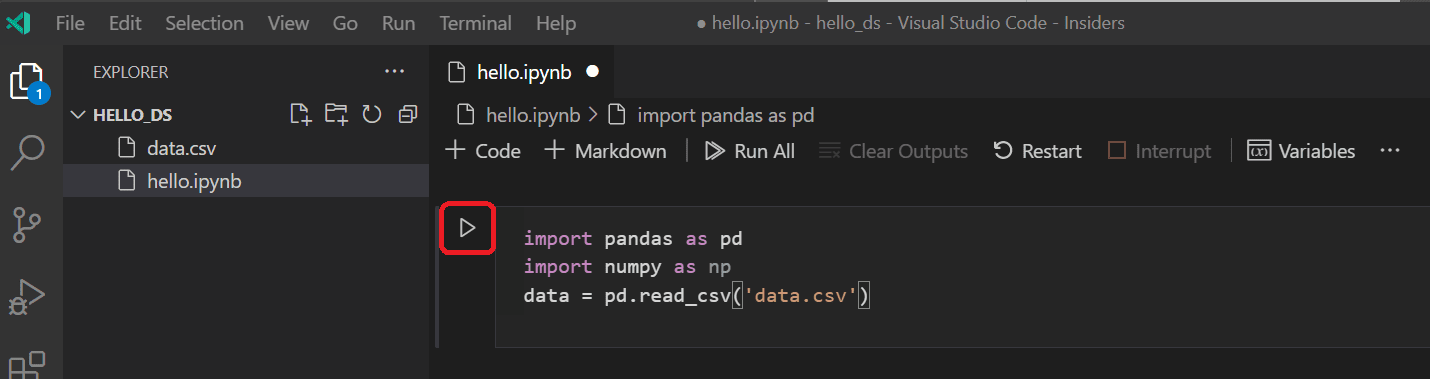
在 Jupyter 笔记本中,首先导入 pandas 和 numpy 库,这两个库是用于操作数据的常用库,并将泰坦尼克号数据加载到 pandas DataFrame 中。为此,请将下面的代码复制到笔记本的第一个单元格中。有关在 VS Code 中使用 Jupyter 笔记本的更多指导,请参阅 使用 Jupyter Notebooks 文档。
import pandas as pd import numpy as np data = pd.read_csv('titanic3.csv') -
现在,使用“运行单元格”图标或 Shift+Enter 快捷键运行该单元格。
-
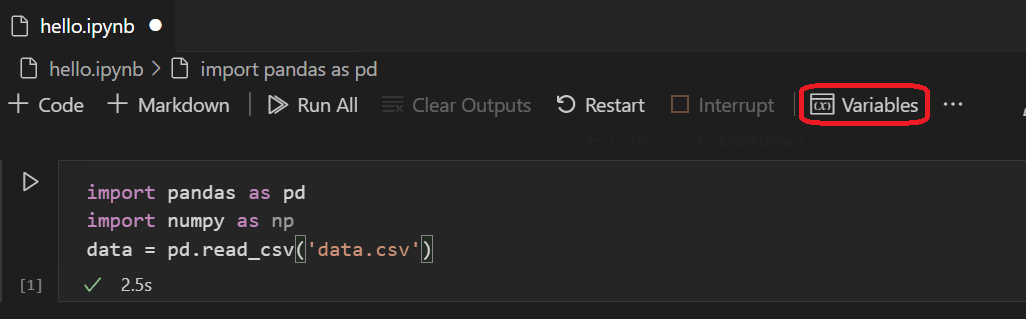
单元格运行完成后,您可以通过“变量资源管理器”和“数据查看器”查看已加载的数据。首先选择笔记本顶部工具栏中的 变量 图标。
-
VS Code 底部将打开一个 JUPYTER: VARIABLES 窗格。其中包含您当前运行的内核中已定义变量的列表。
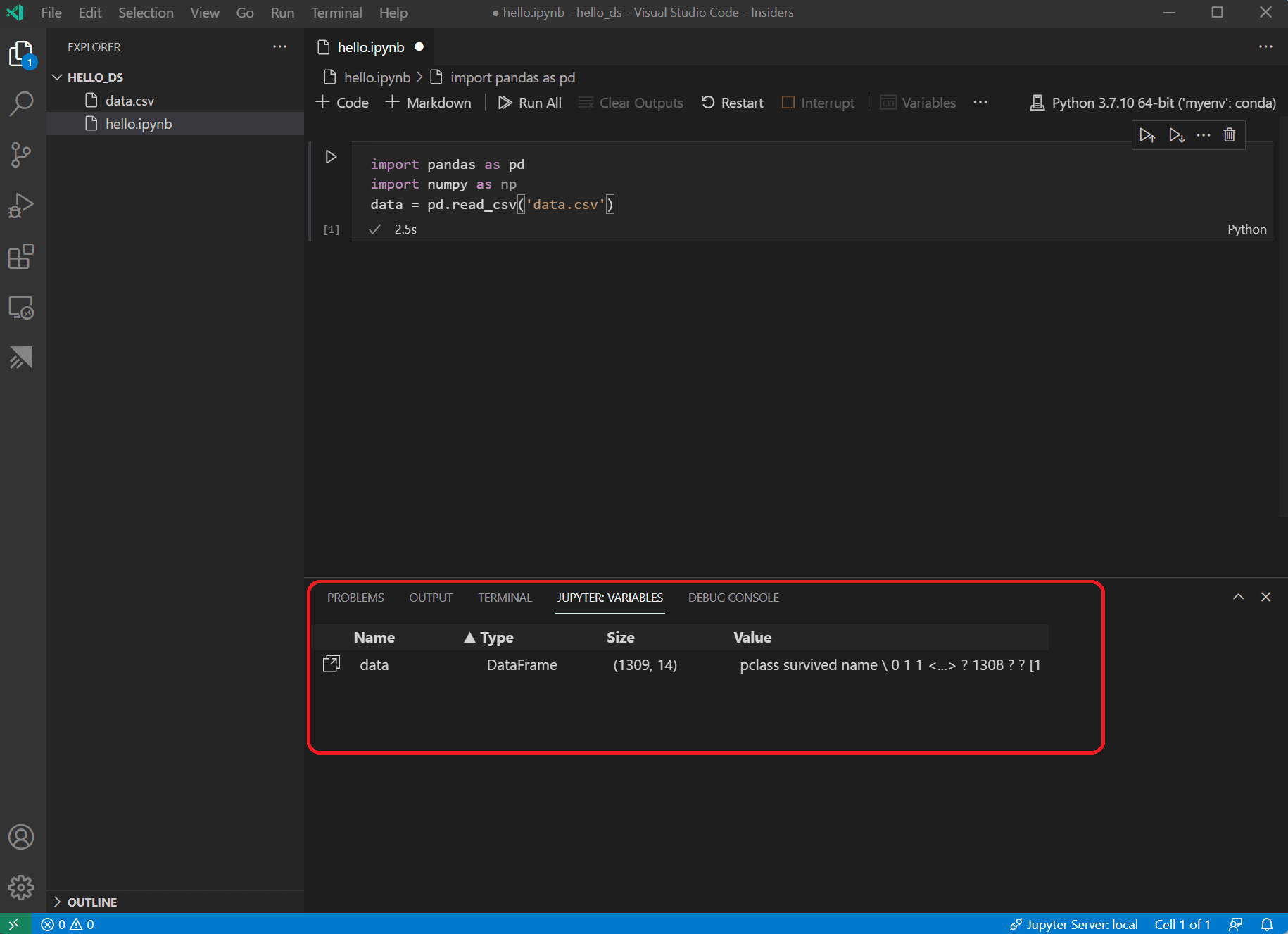
-
要查看之前加载的 Pandas DataFrame 中的数据,请选择
data变量左侧的数据查看器图标。
-
使用数据查看器查看、排序和筛选数据行。在查看数据后,对其中某些方面进行绘图可能有助于可视化不同变量之间的关系。
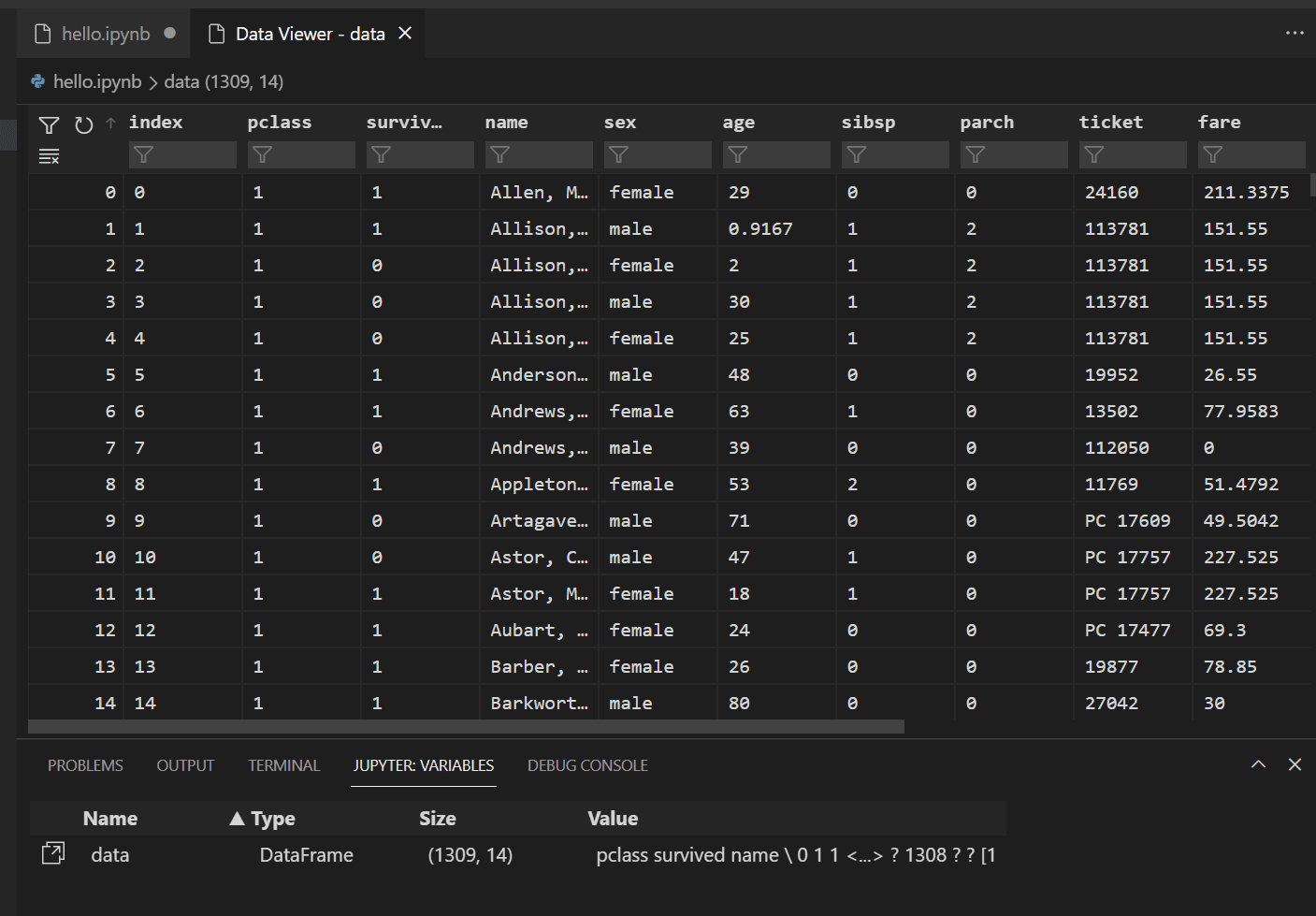
或者,您可以使用其他扩展提供的数据查看体验,例如 Data Wrangler。Data Wrangler 扩展提供了一个丰富的用户界面,可以显示有关您数据见解的信息,并帮助您执行数据分析、质量检查、转换等操作。在我们的文档中了解有关 Data Wrangler 扩展 的更多信息。
-
在可以绘图之前,需要确保数据没有问题。如果您查看泰坦尼克号 CSV 文件,您会注意到一个问号 ("?") 被用来标识数据不可用的单元格。
虽然 Pandas 可以将此值读入 DataFrame,但像 age 这样的列将设置为 object 数据类型而不是数字数据类型,这对于绘图来说是个问题。
可以通过将问号替换为 Pandas 可以理解的缺失值来纠正此问题。将以下代码添加到笔记本的下一个单元格中,以用 numpy NaN 值替换 age 和 fare 列中的问号。请注意,替换值后还需要更新列的数据类型。
提示:要添加新单元格,可以使用现有单元格左下角显示的插入单元格图标。或者,您也可以使用 Esc 进入命令模式,然后按 B 键。
data.replace('?', np.nan, inplace= True) data = data.astype({"age": np.float64, "fare": np.float64})注意:如果您需要查看用于某个列的数据类型,可以使用 DataFrame dtypes 属性。
-
现在数据已准备就绪,您可以使用 seaborn 和 matplotlib 查看数据集中某些列与生存率的关系。将以下代码添加到笔记本的下一个单元格并运行它,以查看生成的图表。
import seaborn as sns import matplotlib.pyplot as plt fig, axs = plt.subplots(ncols=5, figsize=(30,5)) sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0]) sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1]) sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2]) sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3]) sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])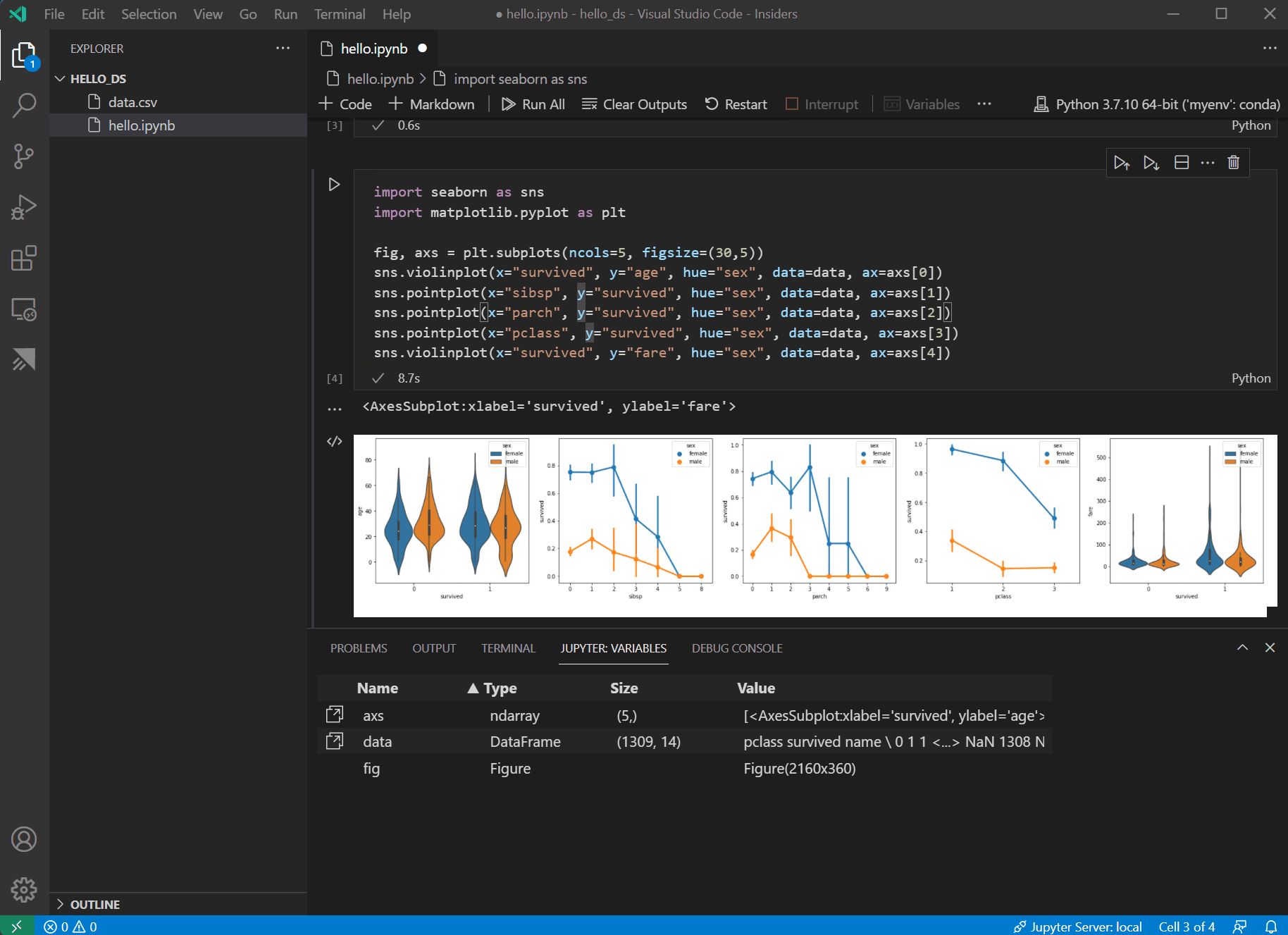
提示:要快速复制图表,可以将鼠标悬停在图表右上角,然后点击出现的 复制到剪贴板 按钮。您还可以通过点击 展开图像 按钮来更好地查看图表的详细信息。

-
这些图表有助于了解生存率与数据输入变量之间的一些关系,但也可以使用 pandas 来计算相关性。为此,所有使用的变量都需要是数值型的,才能进行相关性计算,而当前性别存储为字符串。要将这些字符串值转换为整数,请添加并运行以下代码。
data.replace({'male': 1, 'female': 0}, inplace=True) -
现在,您可以分析所有输入变量之间的相关性,以确定哪些特征最适合作为机器学习模型的输入。值越接近 1,值与结果之间的相关性就越高。使用以下代码将所有变量与生存率之间的关系进行相关性分析。
data.corr(numeric_only=True).abs()[["survived"]]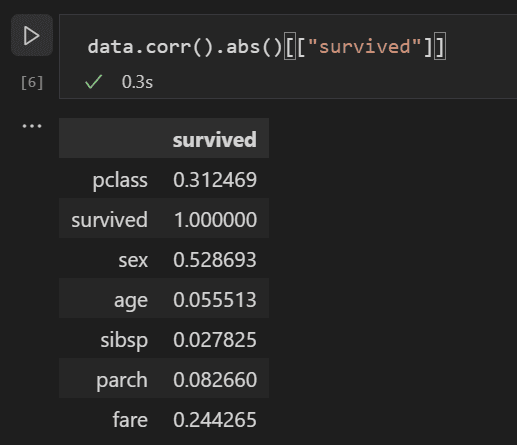
-
查看相关性结果,您会注意到像性别这样的某些变量与生存率具有相当高的相关性,而像亲属(sibsp = 兄弟姐妹或配偶,parch = 父母或子女)之类的其他变量似乎相关性很小。
让我们假设 sibsp 和 parch 在影响生存率方面是相关的,并将它们分组到一个名为“relatives”的新列中,以查看它们的组合是否与生存率具有更高的相关性。为此,您将检查给定乘客的 sibsp 和 parch 的数量是否大于 0,如果是,则可以认为他们有亲属在船上。
使用以下代码在数据集中创建一个名为
relatives的新变量和列,并再次检查相关性。data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1) data.corr(numeric_only=True).abs()[["survived"]]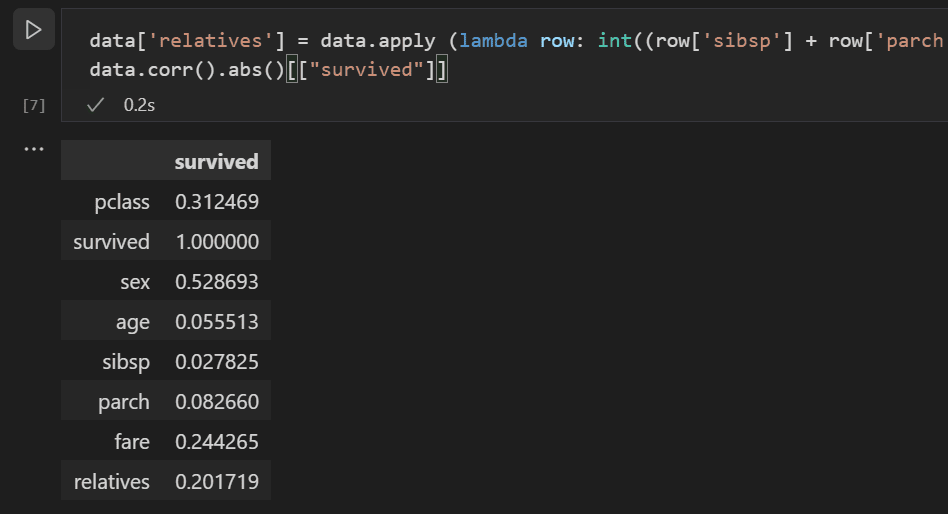
-
您会注意到,实际上,当从一个人是否有亲属的角度来看,而不是看有多少亲属时,与生存率的相关性会更高。有了这些信息,您就可以从数据集中删除低值的 sibsp 和 parch 列,以及任何包含 NaN 值的行,从而得到一个可用于训练模型的数据集。
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()注意:尽管年龄的直接相关性较低,但仍然保留它,因为结合其他输入因素,它可能仍然具有相关性。
训练和评估模型
数据集准备就绪后,您就可以开始创建模型了。在本节中,您将使用 scikit-learn 库(因为它提供了一些有用的辅助函数)来预处理数据集,训练一个分类模型来确定泰坦尼克号的生存率,然后使用该模型和测试数据来确定其准确性。
-
训练模型的第一步通常是将数据集划分为训练数据和验证数据。这允许您使用一部分数据来训练模型,另一部分数据来测试模型。如果您将所有数据都用于训练模型,那么您将无法估计它在模型尚未见过的数据上的实际性能。scikit-learn 库的一个优点是它提供了一个专门用于将数据集拆分为训练数据和测试数据的函数。
在笔记本中添加一个包含以下代码的单元格并运行它,以拆分数据。
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0) -
接下来,您将对输入进行标准化,以便所有特征都被同等对待。例如,在数据集中,age 的值范围为 0-100 左右,而 gender 仅为 1 或 0。通过标准化所有变量,可以确保值范围都相同。在新的代码单元格中使用以下代码来缩放输入值。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.transform(x_test) -
您可以从许多不同的机器学习算法中进行选择来建模数据。scikit-learn 库还支持其中 许多,以及一个 图表 来帮助您选择适合您场景的算法。目前,让我们使用 朴素贝叶斯算法,这是一种常见的分类问题算法。添加一个包含以下代码的单元格来创建和训练算法。
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) -
有了训练好的模型,您现在可以尝试使用从训练中保留的测试数据集。添加并运行以下代码来预测测试数据的结果并计算模型的准确性。
from sklearn import metrics predict_test = model.predict(X_test) print(metrics.accuracy_score(y_test, predict_test))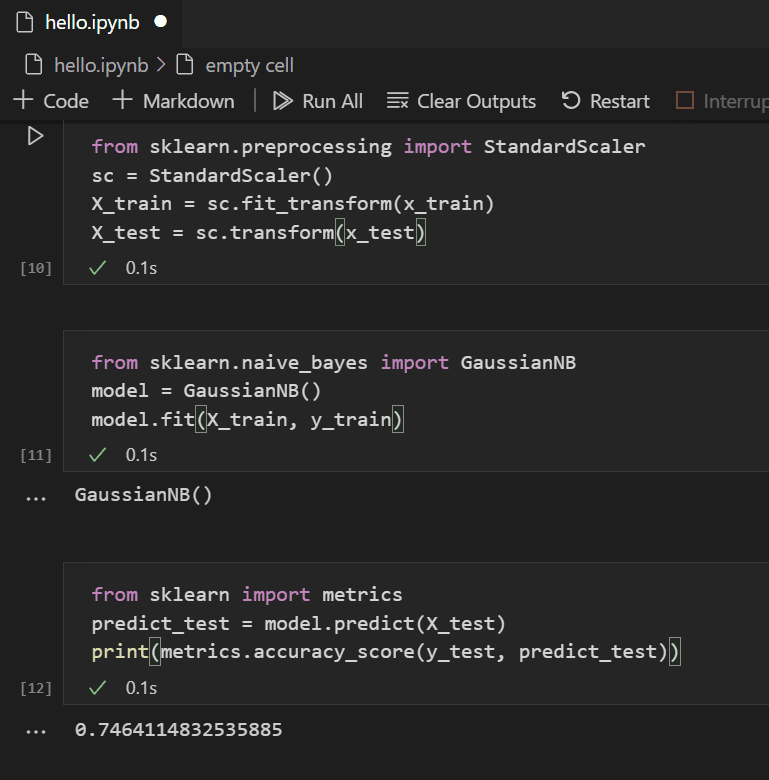
查看测试数据的结果,您会发现训练好的算法在估计生存率方面有约 75% 的成功率。
(可选)使用神经网络
神经网络是一种模型,它使用权重和激活函数,模拟人脑神经元的方面,以根据提供的输入确定结果。与之前查看的机器学习算法不同,神经网络是一种深度学习形式,在这种形式下,您不需要提前知道您问题集的理想算法。它可以用于许多不同的场景,分类是其中之一。在本节中,您将使用 Keras 库和 TensorFlow 来构建神经网络,并探索它如何处理泰坦尼克号数据集。
-
第一步是导入所需的库并创建模型。在这种情况下,您将使用 Sequential 神经网络,这是一种分层神经网络,其中有多个层按顺序相互馈送。
from keras.models import Sequential from keras.layers import Dense model = Sequential() -
定义模型后,下一步是添加神经网络的层。目前,让我们保持简单,只使用三层。添加以下代码来创建神经网络的层。
model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu', input_dim = 5)) model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, kernel_initializer = 'uniform', activation = 'sigmoid'))- 第一层将设置为维度为 5,因为您有五个输入:性别、船票等级、年龄、亲属和票价。
- 最后一层必须输出 1,因为您想要一个表示乘客是否会生存的一维输出。
- 中间层保持为 5 是为了简单起见,尽管该值可能不同。
整流线性单元 (relu) 激活函数用作前两层的良好通用激活函数,而 sigmoid 激活函数是最后一层所必需的,因为您想要的输出(乘客是否生存)需要缩放到 0-1 的范围内(乘客生存的概率)。
您也可以使用此代码行查看所构建模型的摘要
model.summary()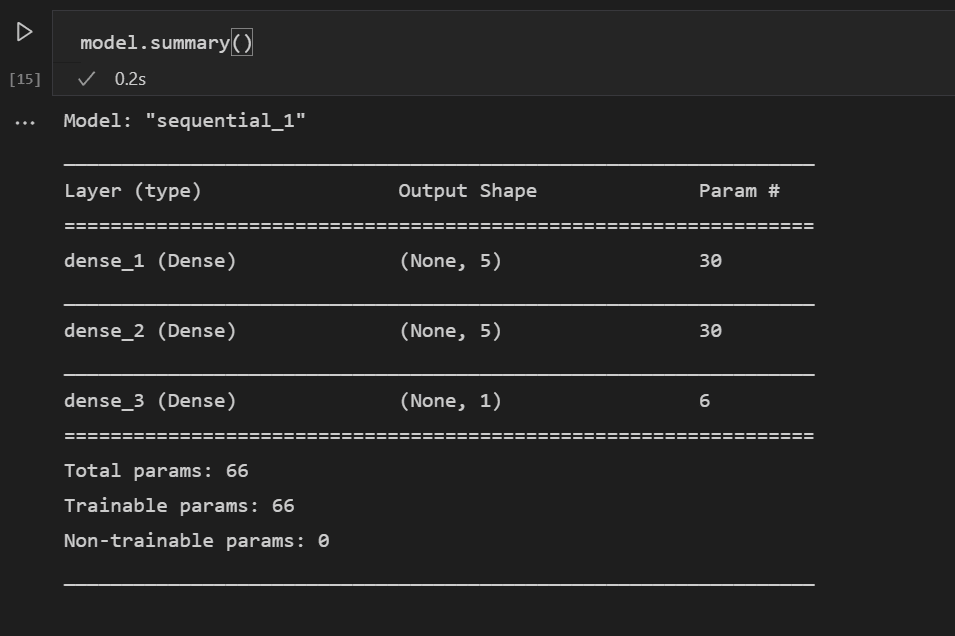
-
模型创建后,需要对其进行编译。作为其中的一部分,您需要定义将使用的优化器类型、如何计算损失以及应优化哪些指标。添加以下代码来构建和训练模型。您会注意到,训练后,准确率为约 61%。
注意:此步骤可能需要几秒钟到几分钟的时间才能完成,具体取决于您的机器。
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, batch_size=32, epochs=50)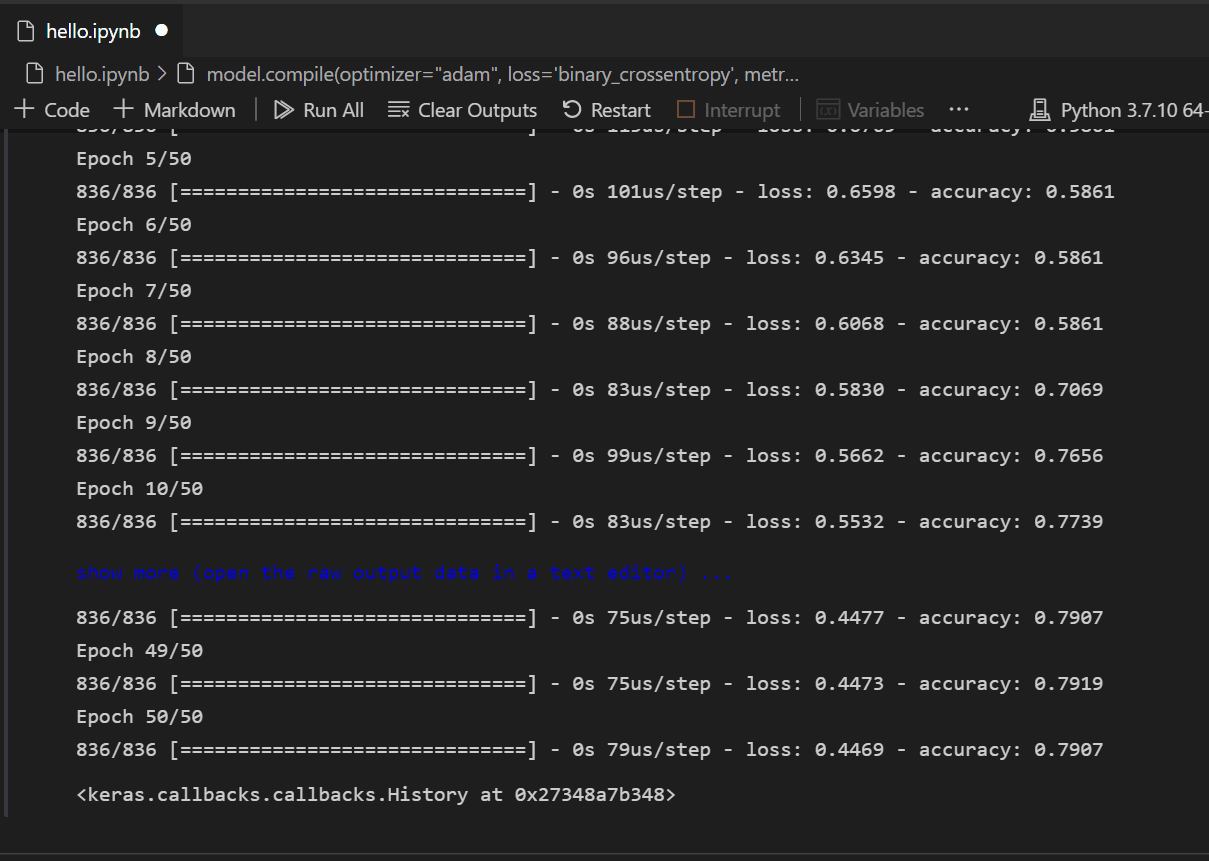
-
模型构建和训练完成后,我们可以查看它在测试数据上的表现。
y_pred = np.rint(model.predict(X_test).flatten()) print(metrics.accuracy_score(y_test, y_pred))
与训练类似,您会注意到现在您在预测乘客生存率方面有 79% 的准确率。使用这个简单的神经网络,结果比之前尝试的朴素贝叶斯分类器的 75% 准确率要好。
后续步骤
现在您已经熟悉了在 Visual Studio Code 中执行机器学习的基础知识,这里有一些其他 Microsoft 资源和教程供您查看。
- 数据科学配置文件模板 - 使用一组精选的扩展、设置和代码片段创建新的 配置文件。
- 了解更多关于在 Visual Studio Code 中使用 Jupyter Notebooks(视频)。
- 开始使用 VS Code 的 Azure 机器学习,利用 Azure 的强大功能部署和优化您的模型。
- 在 Azure Open Data Sets 上查找更多可供探索的数据。