LoRA 微调 Phi Silica
您可以使用低秩适配(LoRA)来微调 Phi Silica 模型,以提高其在特定用例中的性能。通过使用 LoRA 优化 Microsoft Windows 本地语言模型 Phi Silica,您可以获得更准确的结果。此过程包括训练 LoRA 适配器,然后在推理过程中应用它来提高模型的准确性。
Phi Silica 功能在中国不可用。
先决条件
- 您已确定一个用例,用于增强 Phi Silica 的响应。
- 您已选择一个评估标准来决定什么是“良好响应”。
- 您已尝试过 Phi Silica API,但它们不符合您的评估标准。
训练您的适配器
要使用 Windows 11 和 LoRA 适配器微调 Phi Silica 模型,您必须首先生成一个供训练过程使用的数据集。
生成用于 LoRA 适配器的数据集
要生成数据集,您需要将数据分成两个文件
train.json:用于训练适配器。test.json:用于在训练期间和之后评估适配器的性能。
两个文件都必须使用 JSON 格式,其中每一行是一个单独的 JSON 对象,代表一个样本。每个样本应包含用户和助手之间交换的消息列表。
每个消息对象都需要两个字段
content:消息的文本。role:可以是"user"或"assistant",表示发件人。
请参阅以下示例
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
训练技巧
- 每个样本行末尾不需要逗号。
- 包含尽可能多高质量且多样化的示例。为获得最佳效果,请在您的
train.json文件中收集至少几千个训练样本。 test.json文件可以更小,但应涵盖您期望模型处理的交互类型。- 创建
train.json和test.json文件,每行包含一个 JSON 对象,其中包含用户和助手之间简短的来回对话。数据的质量和数量将极大地影响 LoRA 适配器的有效性。
训练 LoRA 适配器
要训练 LoRA 适配器,您需要以下必需的先决条件
- 具有可用配额的 Azure 订阅,位于 Azure 容器应用中。
- 我们建议使用 A100 GPU 或更高级别的 GPU 来高效运行微调作业。
- 检查您在 Azure 门户中是否有可用配额。如果您需要有关查找配额的帮助,请参阅 查看配额。
按照以下步骤创建工作区并启动微调作业
-
导航到 **模型工具 > 微调**,然后选择 **新建项目**。
-
从模型目录中选择 "microsoft/phi-silica",然后选择 **下一步**。
-
在对话框中,选择一个项目文件夹并输入项目名称。项目的新 VS Code 窗口将打开。
-
从方法列表中选择 "LoRA"。
-
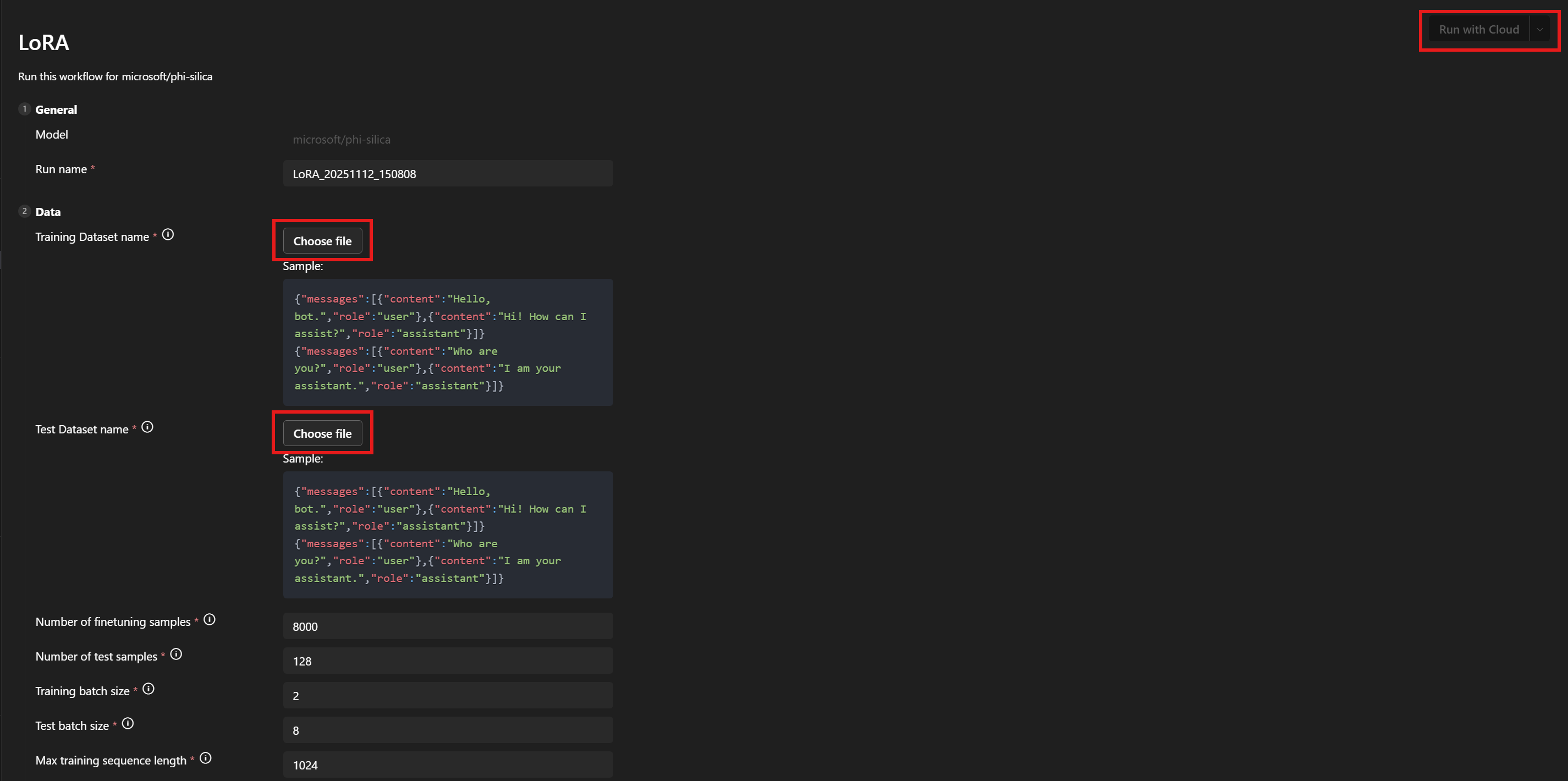
在 **数据 > 训练数据集名称** 和 **测试数据集名称** 下,选择您的
train.json和test.json文件。 -
选择 **使用云运行**。
-
在对话框中,选择用于访问您 Azure 订阅的 Microsoft 帐户。
-
选择完您的帐户后,从订阅下拉菜单中选择一个资源组。
-
您会注意到您的微调作业已成功启动,并显示作业状态。
使用 **刷新** 按钮手动更新状态。微调作业通常平均需要 45-60 分钟才能完成。
-
作业完成后,您可以通过选择 **下载** 来下载新训练的 LoRA 适配器,并通过选择 **显示指标** 来查看微调指标。

LoRA 微调建议
超参数选择
LoRA 微调的默认超参数设置应提供一个合理的基线微调值以供比较。我们已尽力找到适合大多数用例和数据集的默认值。
但是,如果您愿意,我们仍保留了对参数进行扫描的灵活性。
训练超参数
我们的标准参数搜索空间将是
| 参数名称 | 最小值 | 最大值 | 分布 |
|---|---|---|---|
| learning_rate | 1e-4 | 1e-2 | Log-uniform |
| weight_decay | 1e-5 | 1e-1 | Log-uniform |
| adam_beta1 | 0.9 | 0.99 | Uniform |
| adam_beta2 | 0.9 | 0.999 | Uniform |
| adam_epsilon | 1e-9 | 1e-6 | Log-uniform |
| num_warmup_steps | 0 | 10000 | Uniform |
| lora_dropout | 0 | 0.5 | Uniform |
我们还会搜索学习率调度器,选择 linear_with_warmup 或 cosine_with_warmup 之一。如果 num_warmup_steps 参数设置为 0,则可以等效地使用线性或余弦选项。
学习率、学习率调度器和预热步数都相互关联。固定其中两个并改变第三个将使您更深入地了解它们如何改变数据集上训练的输出。
权重衰减和 LoRA Dropout 参数旨在帮助控制过拟合。如果您发现适配器在训练集和评估集上的泛化能力不佳,请尝试增加这些参数的值。
adam_ parameters 影响 Adam 优化器在训练步骤中的行为。有关该优化器的更多信息,请参见例如 PyTorch 文档。
暴露的许多其他参数与其在 PEFT 库中同名的对应参数类似。有关那些的更多信息,请参阅 transformers 文档。
数据超参数
数据超参数 train_nsamples 和 test_nsamples 分别控制训练和测试要使用的样本数。使用更多的训练集样本通常是个好主意。使用更多的测试样本可以得到更少噪声的测试指标,但每次评估运行都会花费更长的时间。
train_batch_size 和 test_batch_size 参数分别控制训练和测试中每个批次应使用的样本数。您通常可以对测试使用比训练更多的批次,因为运行测试样本比训练样本占用的 GPU 内存更少。
train_seqlen 和 test_seqlen 参数控制训练和测试序列的长度。通常,越长越好,直到达到 GPU 内存限制。默认值应能提供良好的平衡。
选择系统提示
我们发现用于选择系统提示的有效策略是保持提示相对简单(一两句话),同时鼓励模型以您想要的格式输出。我们还发现,在训练和推理中使用略有不同的系统提示可以提高结果。
您期望的输出与基础模型差异越大,系统提示就越能帮助您。
例如,如果您仅为基础模型进行轻微的风格更改训练,例如使用简化语言以吸引年轻读者,那么您可能根本不需要系统提示。
但是,如果您的期望输出具有更多结构,那么您将需要使用系统提示来引导模型部分达到目标。因此,如果您需要一个带有特定键的 JSON 表,系统提示的第一句话可以描述当模型以纯语言响应时,响应应该是什么样子。第二句话可以进一步指定 JSON 表的格式。在训练中使用第一句话,然后在推理中使用两句话,可以为您提供想要的结果。
参数
所有可微调的参数列表附在此处。如果某个参数未出现在工作流页面 UI 中,请手动将其添加到 <your_project_path>/<model_name>/lora/lora.yaml。
[
################## Basic config settings ##################
{
"groupId": "data",
"fields": [
{
"name": "system_prompt",
"type": "Optional",
"defaultValue": null,
"info": "Optional system prompt. If specified, the system prompt given here will be prepended to each example in the dataset as the system prompt when training the LoRA adapter. When running inference the same (or a very similar) system prompt should be used. Note: if a system prompt is specified in the training data, giving a system prompt here will overwrite the system prompt in the dataset.",
"label": "System prompt"
},
{
"name": "varied_seqlen",
"type": "bool",
"defaultValue": false,
"info": "Varied sequence lengths in the calibration data. If False (default), training examples will be concatenated together until they are finetune_[train/test]_seqlen tokens long. This makes memory usage more consistent and predictable. If True, each individual example will be truncated to finetune_[train/test]_seqlen tokens. This can sometimes give better training performance, but also gives unpredictable memory usage. It can cause `out of memory` errors mid training, if there are long training examples in your dataset.",
"label": "Allow varied sequence length in data"
},
{
"name": "finetune_dataset",
"type": "str",
"defaultValue": "wikitext2",
"info": "Dataset to finetune on.",
"label": "Dataset name or path"
},
{
"name": "finetune_train_nsamples",
"type": "int",
"defaultValue": 4096,
"info": "Number of samples to load from the train set for finetuning.",
"label": "Number of finetuning samples"
},
{
"name": "finetune_test_nsamples",
"type": "int",
"defaultValue": 128,
"info": "Number of samples to load from the test set for finetuning.",
"label": "Number of test samples"
},
{
"name": "finetune_train_batch_size",
"type": "int",
"defaultValue": 4,
"info": "Batch size for finetuning training.",
"label": "Training batch size"
},
{
"name": "finetune_test_batch_size",
"type": "int",
"defaultValue": 8,
"info": "Batch size for finetuning testing.",
"label": "Test batch size"
},
{
"name": "finetune_train_seqlen",
"type": "int",
"defaultValue": 2048,
"info": "Maximum sequence length for finetuning training. Longer sequences will be truncated.",
"label": "Max training sequence length"
},
{
"name": "finetune_test_seqlen",
"type": "int",
"defaultValue": 2048,
"info": "Maximum sequence length for finetuning testing. Longer sequences will be truncated.",
"label": "Max test sequence length"
}
]
},
{
"groupId": "finetuning",
"fields": [
{
"name": "early_stopping_patience",
"type": "int",
"defaultValue": 5,
"info": "Number of evaluations with no improvement after which training will be stopped.",
"label": "Early stopping patience"
},
{
"name": "epochs",
"type": "float",
"defaultValue": 1,
"info": "Number of total epochs to run.",
"label": "Epochs"
},
{
"name": "eval_steps",
"type": "int",
"defaultValue": 64,
"info": "Number of training steps to perform before each evaluation.",
"label": "Steps between evaluations"
},
{
"name": "save_steps",
"type": "int",
"defaultValue": 64,
"info": "Number of steps after which to save model checkpoint. This _must_ be a multiple of the number of steps between evaluations.",
"label": "Steps between checkpoints"
},
{
"name": "learning_rate",
"type": "float",
"defaultValue": 0.0002,
"info": "Learning rate for training.",
"label": "Learning rate"
},
{
"name": "lr_scheduler_type",
"type": "str",
"defaultValue": "linear",
"info": "Type of learning rate scheduler.",
"label": "Learning rate scheduler",
"optionValues": [
"linear",
"linear_with_warmup",
"cosine",
"cosine_with_warmup"
]
},
{
"name": "num_warmup_steps",
"type": "int",
"defaultValue": 400,
"info": "Number of warmup steps for learning rate scheduler. Only relevant for a _with_warmup scheduler.",
"label": "Scheduler warmup steps (if supported)"
}
]
}
################## Advanced config settings ##################
{
"groupId": "advanced",
"fields": [
{
"name": "seed",
"type": "int",
"defaultValue": 42,
"info": "Seed for sampling the data.",
"label": "Random seed"
},
{
"name": "evaluation_strategy",
"type": "str",
"defaultValue": "steps",
"info": "Evaluation strategy to use.",
"label": "Evaluation strategy",
"optionValues": [
"steps",
"epoch",
"no"
]
},
{
"name": "lora_dropout",
"type": "float",
"defaultValue": 0.1,
"info": "Dropout rate for LoRA.",
"label": "LoRA dropout"
},
{
"name": "adam_beta1",
"type": "float",
"defaultValue": 0.9,
"info": "Beta1 hyperparameter for Adam optimizer.",
"label": "Adam beta 1"
},
{
"name": "adam_beta2",
"type": "float",
"defaultValue": 0.95,
"info": "Beta2 hyperparameter for Adam optimizer.",
"label": "Adam beta 2"
},
{
"name": "adam_epsilon",
"type": "float",
"defaultValue": 1e-08,
"info": "Epsilon hyperparameter for Adam optimizer.",
"label": "Adam epsilon"
},
{
"name": "num_training_steps",
"type": "Optional",
"defaultValue": null,
"info": "The number of training steps there will be. If not set (recommended), this will be calculated internally.",
"label": "Number of training steps"
},
{
"name": "gradient_accumulation_steps",
"type": "int",
"defaultValue": 1,
"info": "Number of updates steps to accumulate before performing a backward/update pass.",
"label": "gradient accumulation steps"
},
{
"name": "eval_accumulation_steps",
"type": "Optional",
"defaultValue": null,
"info": "Number of predictions steps to accumulate before moving the tensors to the CPU.",
"label": "eval accumulation steps"
},
{
"name": "eval_delay",
"type": "Optional",
"defaultValue": 0,
"info": "Number of epochs or steps to wait for before the first evaluation can be performed, depending on the eval_strategy.",
"label": "eval delay"
},
{
"name": "weight_decay",
"type": "float",
"defaultValue": 0.0,
"info": "Weight decay for AdamW if we apply some.",
"label": "weight decay"
},
{
"name": "max_grad_norm",
"type": "float",
"defaultValue": 1.0,
"info": "Max gradient norm.",
"label": "max grad norm"
},
{
"name": "gradient_checkpointing",
"type": "bool",
"defaultValue": false,
"info": "If True, use gradient checkpointing to save memory at the expense of slower backward pass.",
"label": "gradient checkpointing"
}
]
}
]
修改 Azure 订阅和资源组
如果要修改之前设置的 Azure 订阅和资源组,可以在 <your_project_path>/model_lab.workspace.provision.config 文件中进行更新或删除。
使用 Phi Silica LoRA 适配器进行推理
Phi Silica API 是有限访问功能的一部分(请参阅 LimitedAccessFeatures 类)。有关更多信息或请求解锁令牌,请使用 LAF 访问令牌请求表。
目前,Phi Silica LoRA 适配器的推理仅支持装有 ARM 处理器的 Copilot+ PC。
使用 Windows AI API 进行推理:Phi Silica 与 LoRA 适配器