括号对颜色高亮速度提升 10,000 倍
2021 年 9 月 29 日,作者 Henning Dieterichs,@hediet_dev
在 Visual Studio Code 中处理深度嵌套的括号时,很难弄清楚哪些括号匹配,哪些不匹配。
为了让这一点更容易,在 2016 年,一位名叫 CoenraadS 的用户开发了出色的 Bracket Pair Colorizer 扩展,用于为匹配的括号着色,并将其发布到 VS Code Marketplace。这个扩展变得非常流行,现在是 Marketplace 上下载量排名前 10 的扩展之一,安装量超过 600 万。
为了解决性能和准确性问题,2018 年,CoenraadS 又推出了 Bracket Pair Colorizer 2,目前安装量也超过 300 万。
Bracket Pair Colorizer 扩展是 VS Code 可扩展性强大功能的一个很好的例子,它大量使用了 Decoration API 来为括号着色。

我们很高兴看到 VS Code Marketplace 提供了更多此类社区提供的扩展,所有这些扩展都以非常有创意的方式帮助识别匹配的括号对,包括:Rainbow Brackets、Subtle Match Brackets、Bracket Highlighter、Blockman 和 Bracket Lens。这些多样化的扩展表明 VS Code 用户确实渴望获得更好的括号支持。
性能问题
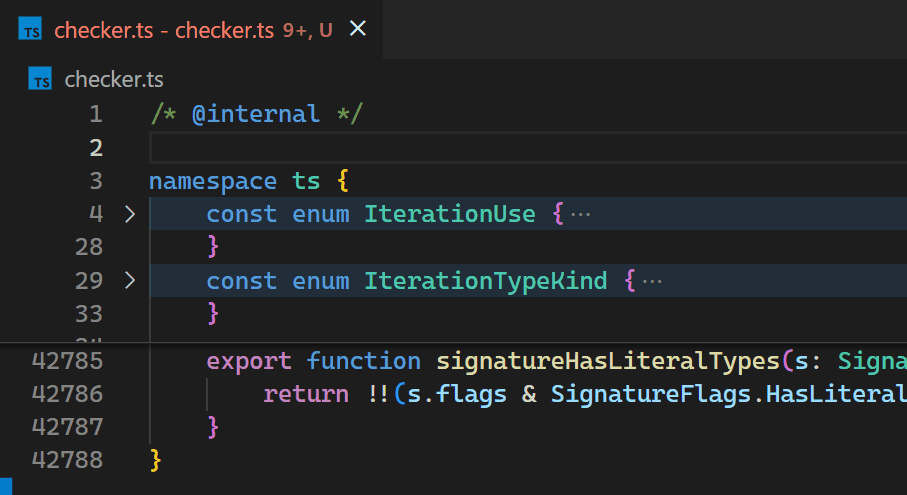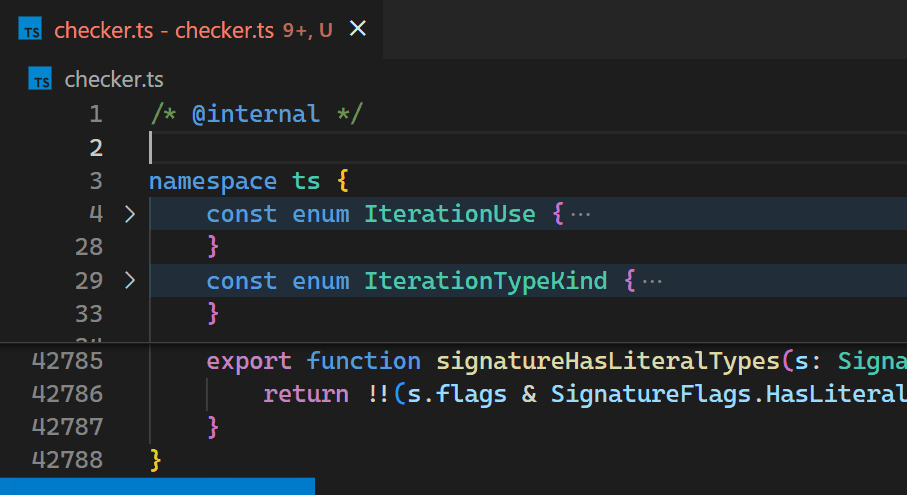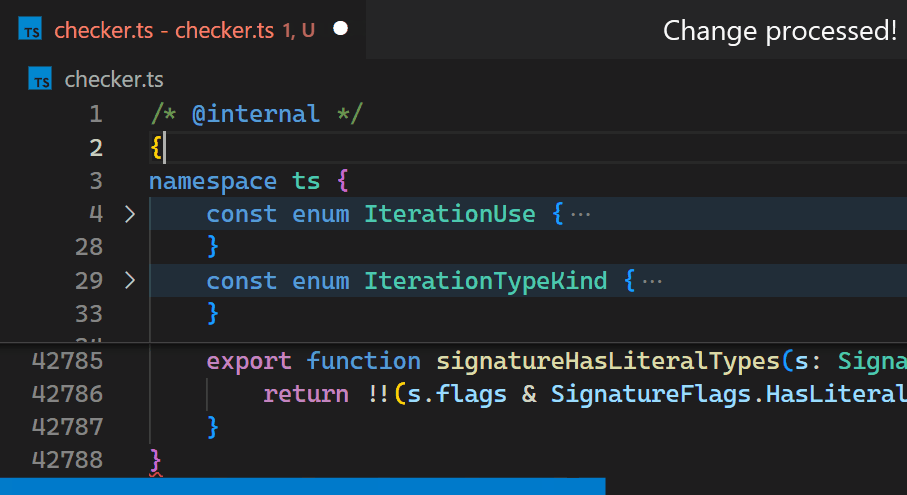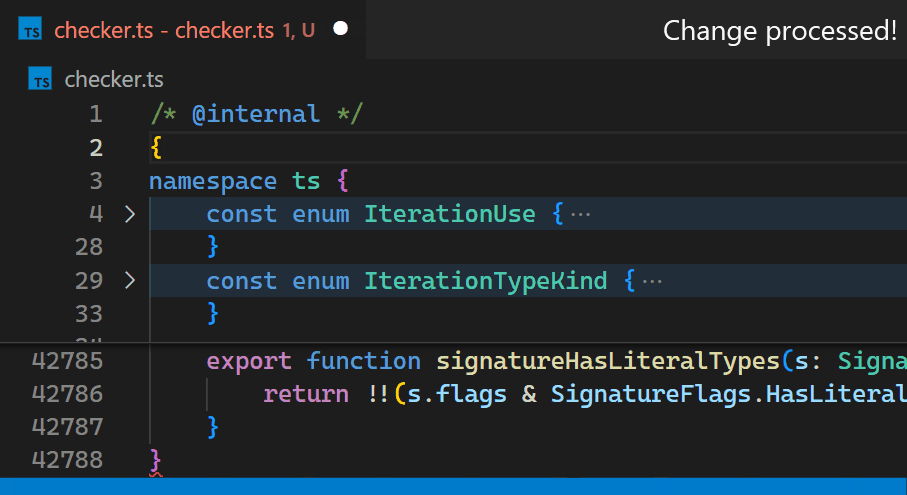
不幸的是,Decoration API 的非增量特性以及缺少对 VS Code 令牌信息的访问,导致 Bracket Pair Colorizer 扩展在处理大文件时速度缓慢:当在 TypeScript 项目的 checker.ts 文件(包含超过 42k 行代码)开头插入单个括号时,需要大约 10 秒才能更新所有括号对的颜色。在这 10 秒的处理过程中,扩展主机进程的 CPU 占用率达到 100%,所有由扩展提供支持的功能(例如自动补全或诊断)都会停止工作。幸运的是,VS Code 的架构确保了 UI 保持响应,并且文档仍然可以保存到磁盘。
CoenraadS 意识到了这个性能问题,并投入了大量精力在扩展的第 2 版中提高了速度和准确性,通过重用 VS Code 的令牌和括号解析引擎。然而,VS Code 的 API 和扩展架构并非旨在在涉及数十万个括号对时实现高性能的括号对颜色高亮。因此,即使在 Bracket Pair Colorizer 2 中,在文件开头插入 { 之后,颜色反映新的嵌套级别也需要一些时间
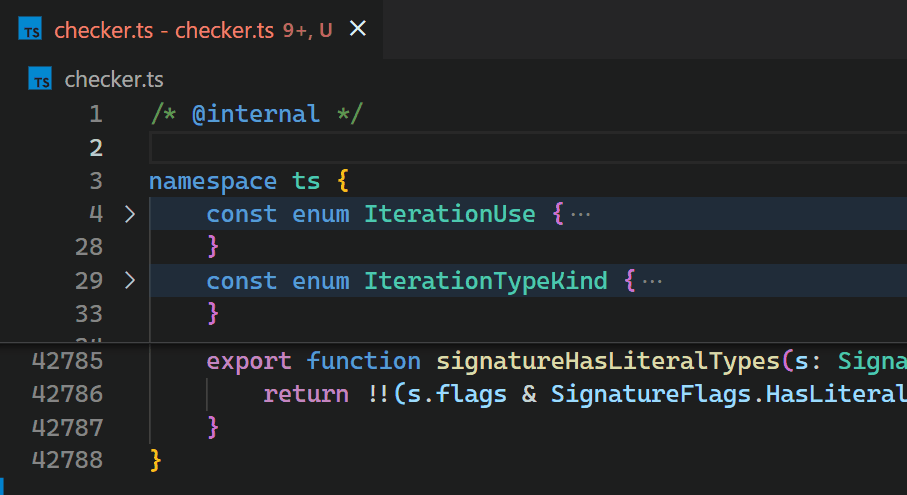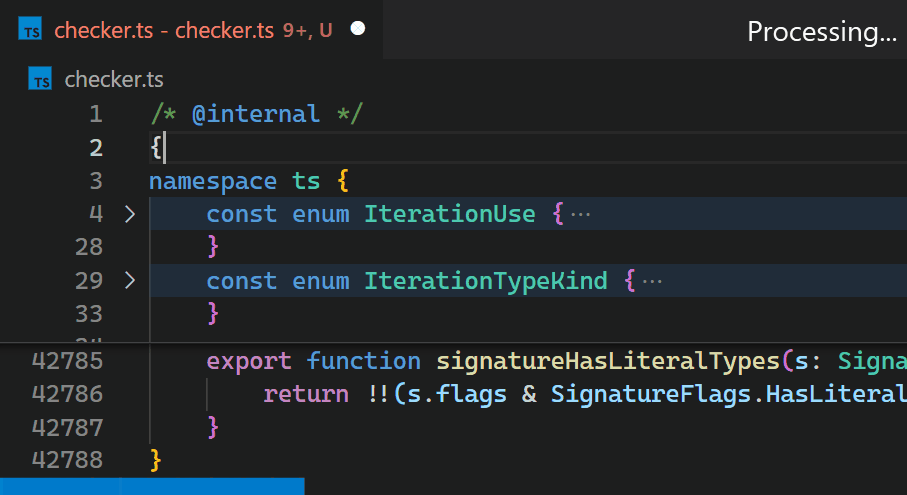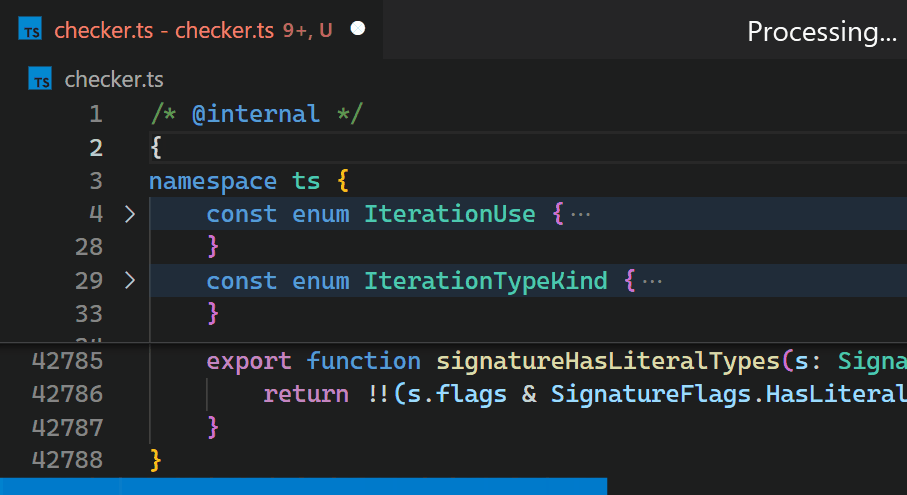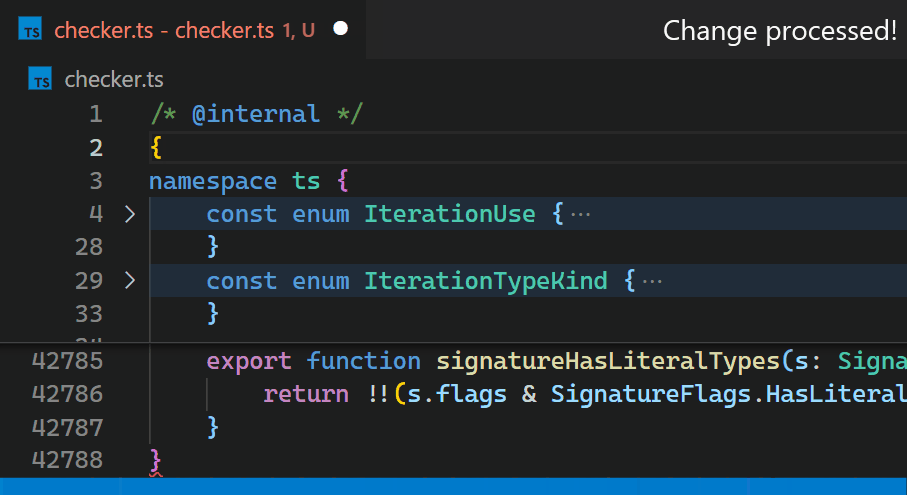
虽然我们很乐意只改进扩展的性能(这肯定需要引入更高级的 API,针对高性能场景进行优化),但渲染器和扩展主机之间的异步通信严重限制了作为扩展实现时括号对颜色高亮的快慢。这个限制无法克服。特别是,不应在它们出现在视口中时立即异步请求括号对颜色,因为这会在滚动大文件时导致明显的闪烁。有关此问题的讨论可以在 问题 #128465 中找到。
我们做了什么
相反,在 1.60 更新中,我们在 VS Code 的核心中重新实现了该扩展,并将这个时间缩短到不到一毫秒——在这个特定的例子中,速度提高了 10,000 多倍。
可以通过添加设置 "editor.bracketPairColorization.enabled": true 来启用该功能。
现在,即使对于包含数十万个括号对的文件,更新也几乎察觉不到。请注意,在第 2 行输入 { 后,第 42,788 行中的括号颜色会立即反映新的嵌套级别
一旦我们决定将其移入核心,我们还借此机会研究了如何使其尽可能快。谁不喜欢算法挑战呢?
在不受公共 API 设计限制的情况下,我们可以使用 (2,3)-树、无递归树遍历、位运算、增量解析和其他技术来减少扩展在最坏情况下的更新 时间复杂度(即当文档已经打开时处理用户输入所需的时间),从
此外,通过重用渲染器中的现有令牌及其增量令牌更新机制,我们获得了另一个巨大的(但恒定的)速度提升。
Web 版 VS Code
除了性能更高之外,新的实现还支持 VS Code for the Web,您可以在 vscode.dev 和 github.dev 中看到它的实际应用。由于 Bracket Pair Colorizer 2 重用 VS Code 令牌引擎的方式,无法将该扩展迁移到我们所说的 web extension。
我们的新实现不仅适用于 VS Code for the Web,也直接适用于 Monaco Editor!
括号对颜色高亮的挑战
括号对颜色高亮的全部意义在于快速确定视口中所有括号及其(绝对)嵌套级别。视口可以描述为文档中的一个范围,以行号和列号表示,通常只占整个文档的一小部分。
不幸的是,括号的嵌套级别取决于它前面的*所有*字符:将任何字符替换为开括号“{”通常会增加后面所有括号的嵌套级别。
因此,当最初为文档末尾的括号着色时,必须处理整个文档的每一个字符。

bracket pair colorizer 扩展中的实现通过在插入或删除单个括号时再次处理整个文档来解决这个挑战(这对于小文档来说是非常合理的)。然后必须使用 VS Code Decoration API 删除并重新应用颜色,该 API 将所有颜色装饰发送到渲染器。
如前所述,这对于包含数十万个括号对(以及同样多的颜色装饰)的大文档来说是很慢的。因为扩展无法增量更新装饰,必须一次性替换所有装饰,所以 bracket pair colorizer 扩展也无法做得更好。尽管如此,渲染器以一种巧妙的方式组织所有这些装饰(使用所谓的 interval tree),因此在收到(可能数十万个)装饰后,渲染速度总是很快的。
我们的目标是不必在每次按键时重新处理整个文档。相反,处理单个文本编辑所需的时间应该只随文档长度呈(多重)对数增长。
然而,我们仍然希望能够以(多重)对数时间查询视口中的所有括号及其嵌套级别,就像使用 VS Code 的 decoration API(它使用前面提到的 interval tree)一样。
算法复杂度
请随意跳过有关算法复杂度的部分。
在下文中,
然而,我们允许文档首次打开时的初始化时间复杂度为
语言语义使括号对颜色高亮变得困难
真正使括号对颜色高亮变得困难的是根据文档语言检测实际的括号。特别是,我们不希望检测注释或字符串中的开括号或闭括号,如下面的 C 示例所示
{ /* } */ char str[] = "}"; }
只有第三个出现的“}”才关闭括号对。
对于令牌语言不规则的语言(例如带有 JSX 的 TypeScript)来说,这变得更加困难

[1] 处的括号是否与 [2] 处或 [3] 处的括号匹配?这取决于模板文字表达式的长度,只有具有无限状态(即非规则分词器)的分词器才能正确确定。
令牌来救援
幸运的是,语法高亮必须解决一个类似的问题:在前面的代码片段中,[2] 处的括号应该渲染为字符串还是纯文本?
事实证明,忽略语法高亮识别的注释和字符串中的括号对于大多数括号对来说效果足够好。< ... > 是我们迄今为止发现的唯一有问题的一对,因为这些括号通常既用于比较,也用作泛型类型的对,同时具有相同的令牌类型。
VS Code 已经有一个高效的同步机制来维护用于语法高亮的令牌信息,我们可以重用它来识别开括号和闭括号。
这是 Bracket Pair Colorization 扩展面临的另一个挑战,它对性能产生负面影响:它无法访问这些令牌,必须自己重新计算它们。我们考虑了很久如何有效地、可靠地将令牌信息暴露给扩展,但得出的结论是,如果不将大量实现细节泄露到扩展 API 中,我们就无法做到这一点。因为扩展仍然必须为文档中的每个括号发送一个颜色装饰列表,所以仅凭这样的 API 甚至无法解决性能问题。
作为旁注,当在文档开头应用编辑(例如为 C-like 语言插入 /*)更改所有后续令牌时,VS Code 不会一次性重新分词长文档,而是随着时间分块进行。这确保了 UI 不会冻结,即使分词是在渲染器中同步发生的。
基本算法
核心思想是使用递归下降解析器来构建抽象语法树 (AST),描述所有括号对的结构。当找到一个括号时,检查令牌信息,如果它在注释或字符串中,则跳过该括号。分词器允许解析器查看和读取此类括号或文本令牌。
现在的技巧是只存储每个节点的长度(并且为所有非括号的内容提供文本节点以填补空白),而不是存储绝对开始/结束位置。仅有长度可用,仍然可以有效地在 AST 中定位给定位置的括号节点。
下图显示了一个带有长度注释的示例 AST

将其与使用绝对开始/结束位置的经典 AST 表示进行比较

两个 AST 描述了相同的文档,但在遍历第一个 AST 时,必须即时计算绝对位置(这很容易做到),而在第二个 AST 中它们已经预先计算好了。
然而,当在第一个树中插入单个字符时,只需更新节点本身的长度及其所有父节点的长度——所有其他长度保持不变。
当像第二个树中那样存储绝对位置时,文档中后面*每个*节点的位置都必须递增。
此外,通过不存储绝对偏移量,可以共享具有相同长度的叶节点以避免分配。
这是带有长度注释的 AST 在 TypeScript 中的定义方式
type Length = ...;
type AST = BracketAST | BracketPairAST | ListAST | TextAST;
/** Describes a single bracket, such as `{`, `}` or `begin` */
class BracketAST {
constructor(public length: Length) {}
}
/** Describes a matching bracket pair and the node in between, e.g. `{...}` */
class BracketPairAST {
constructor(
public openingBracket: BracketAST;
public child: BracketPairAST | ListAST | TextAST;
public closingBracket: BracketAST;
) {}
length = openingBracket.length + child.length + closingBracket.length;
}
/** Describes a list of bracket pairs or text nodes, e.g. `()...()` */
class ListAST {
constructor(
public items: Array<BracketPairAST | TextAST>
) {}
length = items.sum(item => item.length);
}
/** Describes text that has no brackets in it. */
class TextAST {
constructor(public length: Length) {}
}
查询这样的 AST 以列出视口中的所有括号及其嵌套级别相对简单:执行深度优先遍历,即时计算当前节点的绝对位置(通过加上前面节点的长度),并跳过完全在请求范围之前或之后的节点的子节点。
这个基本算法已经起作用了,但还有一些悬而未决的问题
- 我们如何确保查询给定范围内的所有括号具有所需的对数性能?
- 输入时,我们如何避免从头开始构建新的 AST?
- 我们如何处理令牌块更新?当打开大文档时,令牌最初不可用,而是分块传入。
确保查询时间是对数的
当查询给定范围内的括号时,真正长的列表会破坏性能:我们无法对它们的子节点进行快速二分查找以跳过所有不相关的非相交节点,因为我们需要对每个节点的长度求和才能即时计算绝对位置。在最坏的情况下,我们需要遍历所有节点。
在下面的示例中,我们必须查看 13 个节点(蓝色)才能找到位置 24 处的括号

虽然我们可以计算并缓存长度总和以启用二分查找,但这与存储绝对位置有相同的问题:每次单个节点增长或缩小时,我们都需要重新计算所有这些值,这对于非常长的列表来说成本很高。
相反,我们允许列表将其他列表作为子节点
class ListAST {
constructor(public items: Array<ListAST | BracketPairAST | TextAST>) {}
length = items.sum(item => item.length);
}
这如何改善情况?
如果我们能确保每个列表只有有限数量的子节点并类似于对数高度的平衡树,事实证明这足以获得查询括号所需的对数性能。
保持列表树平衡
我们使用 (2,3)-树 来强制这些列表平衡:每个列表必须至少有 2 个且至多 3 个子节点,并且列表的所有子节点在平衡列表树中必须具有相同的高度。请注意,括号对在平衡树中被视为高度为 0 的叶子,但它可能在 AST 中有子节点。
在初始化期间从头构建 AST 时,我们首先收集所有子节点,然后将它们转换为这样的平衡树。这可以在线性时间内完成。
前面示例的可能 (2,3)-树可能如下所示。请注意,我们现在只需要查看 8 个节点(蓝色)即可找到位置 24 处的括号对,并且列表是具有 2 个还是 3 个子节点有一些自由度

最坏情况复杂度分析
请随意跳过有关算法复杂度的部分。
目前,我们假设每个列表都类似于 (2,3)-树,因此最多有 3 个子节点。
为了最大化查询时间,我们来看一个具有
{
{
... O(log N) many nested bracket pairs
{
{} [1]
}
...
}
}
尚未涉及列表,但我们已经需要遍历
现在,在最坏的情况下,我们通过在每个嵌套的括号对中插入额外的
{}{}{}{}{}{}{}{}... O(N / log N) many
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{
... O(log N) many nested bracket pairs
{
{}{}{}{}{}{}{}{}... O(N / log N) many
{} [1]
}
...
}
}
同一嵌套级别的每个括号列表都会产生一个高度为
的树。因此,要找到 [1] 处的节点,我们必须遍历
因此,查询括号的最坏情况时间复杂度为
这也表明 AST 的最大高度为
增量更新
高性能括号对颜色高亮最有趣的问题仍然悬而未决:给定当前的(平衡)AST 和替换某个范围的文本编辑,我们如何有效地更新树以反映文本编辑?
我们的想法是重用用于初始化的递归下降解析器,并添加缓存策略,以便可以重用和跳过不受文本编辑影响的节点。
当递归下降解析器解析位置
下面的示例显示了插入单个开括号时哪些节点可以重用(绿色)(省略了单个括号节点)

通过重新解析包含编辑的节点并重用所有未更改的节点来处理文本编辑后,更新后的 AST 如下所示。请注意,通过消耗 3 个节点 B、H 和 G,可以重用所有 11 个可重用节点,并且只需要重新创建 4 个节点(橙色)

如本例所示,平衡列表不仅使查询速度快,而且有助于一次重用大块节点。
算法复杂度
请随意跳过有关算法复杂度的部分。
让我们假设文本编辑替换了大小至多为
我们只需要重新解析与编辑范围相交的节点。因此,最多需要重新解析
显然,如果一个节点不与编辑范围相交,那么它的任何子节点也不相交。因此,我们只需要考虑重用不与编辑范围相交但其父节点相交的节点(这将隐式重用所有节点及其父节点都不与编辑范围相交的节点)。此外,此类父节点不能被编辑范围完全覆盖,否则它们的所有子节点都将与编辑范围相交。然而,AST 中的每一层最多只有两个节点部分与编辑范围相交。由于 AST 最多有
因此,要构建更新后的树,我们最多需要重新解析
这也决定了更新操作的时间复杂度,但有一个注意事项。
我们如何重新平衡 AST?
不幸的是,最后一个示例中的树不再平衡了。
当将重用的列表节点与新解析的节点组合时,我们必须做一些工作来维护 (2,3)-树属性。我们知道重用和新解析的节点都已经 (2,3)-树,但它们可能具有不同的高度——所以我们不能只创建父节点,因为 (2,3)-树节点的所有子节点都必须具有相同的高度。
我们如何有效地将所有这些具有混合高度的节点连接成一个单个的 (2,3)-树?
这可以很容易地简化为将较小的树前置或附加到较大的树的问题:如果两棵树具有相同的高度,则创建包含两个子节点的列表就足够了。否则,我们将高度为
因为这具有运行时
为了平衡上一个示例中的列表 α 和 γ,我们对其子节点执行连接操作(红色列表违反 (2,3)-树属性,橙色节点高度意外,绿色节点在重新平衡时重新创建)

因为列表 B 在不平衡树中的高度为 2,而括号对 β 的高度为 0,所以我们需要将 β 附加到 B,并完成列表 α。剩余的 (2,3)-树是 B,因此它成为新的根并替换列表 α。继续处理 γ,其子节点 δ 和 H 的高度为 0,而 G 的高度为 1。
我们首先连接 δ 和 H,并创建高度为 1 的新父节点 Y(因为 δ 和 H 具有相同的高度)。然后我们连接 Y 和 G,并创建新的父列表 X(出于同样的原因)。然后 X 成为父括号对的新子节点,替换不平衡的列表 γ。
在这个例子中,平衡操作有效地将最顶层列表的高度从 3 减少到 2。然而,AST 的总高度从 4 增加到 5,这对最坏情况查询时间产生负面影响。这是由括号对 β 引起的,它在平衡列表树中充当叶子,但实际上包含另一个高度为 2 的列表。
在平衡父列表时考虑 β 的内部 AST 高度可以改善最坏情况,但这将脱离 (2,3)-树的理论。
算法复杂度
请随意跳过有关算法复杂度的部分。
我们必须连接至多
因为连接两个不同高度的节点的时间复杂度为
我们如何有效地找到可重用节点?
我们有两个数据结构用于此任务:*编辑前位置映射器*和*节点读取器*。
位置映射器将新文档中的位置(应用编辑后)映射到旧文档中的位置(应用编辑前),如果可能的话。它还告诉我们当前位置与下一个编辑之间的长度(如果我们处于编辑中,则为 0)。这可以在
中完成。当处理文本编辑和解析节点时,该组件为我们提供了可以潜在重用的节点位置及其最大允许长度——显然,我们想要重用的节点必须短于到下一个编辑的距离。
节点读取器可以快速找到 AST 中在给定位置满足给定谓词的最长节点。为了找到我们可以重用的节点,我们使用位置映射器来查找其旧位置及其最大允许长度,然后使用节点读取器来查找该节点。如果我们找到了这样的节点,我们就知道它没有改变,可以重用它并跳过它的长度。
因为节点读取器是以单调递增的位置查询的,所以它不必每次都从头开始搜索,而是可以从上一个重用节点的末尾开始搜索。实现这一点的关键是无递归的树遍历算法,它可以深入节点,也可以跳过节点或返回父节点。当找到一个可重用节点时,遍历停止并继续下一个对节点读取器的请求。
单次查询节点读取器的复杂度高达
令牌更新
当在不包含文本 */ 的长 C 风格文档开头插入 /* 时,整个文档会变成一个注释,所有令牌都会更改。
因为令牌是在渲染器进程中同步计算的,所以不能一次性重新分词而不会冻结 UI。
相反,令牌是随时间分批更新的,这样 JavaScript 事件循环就不会被阻塞太久。虽然这种方法不会减少总阻塞时间,但它提高了更新过程中 UI 的响应能力。最初对文档进行分词时也使用相同的机制。
幸运的是,由于括号对 AST 的增量更新机制,我们可以立即应用此类分批令牌更新,方法是将更新视为单个文本编辑,该编辑将重新分词的范围替换为自身。一旦所有令牌更新都传入,括号对 AST 就保证处于与从头开始创建时相同的状态——即使在重新分词进行时用户编辑了文档。
这样,不仅分词即使文档中的所有令牌都更改也具有高性能,而且括号对颜色高亮也具有高性能。
然而,当文档在注释中包含大量不平衡的括号时,文档末尾的括号颜色可能会闪烁,因为括号对解析器会发现这些括号应该被忽略。
为了避免打开文档并导航到其末尾时括号对颜色闪烁,我们在初始分词过程完成之前维护两个括号对 AST。第一个 AST 是在没有令牌信息的情况下构建的,并且不接收令牌更新。第二个 AST 最初是第一个 AST 的克隆,但接收令牌更新,并随着分词的进行和令牌更新的应用而越来越偏离。最初,第一个 AST 用于查询括号,但一旦文档完全分词,第二个 AST 就会接管。
因为深度克隆几乎与重新解析文档一样昂贵,所以我们实现了写入时复制,从而实现了
中进行克隆。
长度编码
编辑器视图用行号和列号描述视口。颜色装饰也期望以基于行/列的范围表示。
中完成),我们也对 AST 使用基于行/列的长度。
请注意,此方法与直接按行索引的数据结构(例如使用字符串数组描述文档的行内容)有显着不同。特别是,这种方法可以在行之间和行内进行单个二分查找。
添加两个这样的长度很容易,但需要区分情况:虽然行数直接相加,但只有当第二个长度跨越零行时,第一个长度的列数才包含在内。
令人惊讶的是,大多数代码不需要知道长度是如何表示的。只有位置映射器变得明显更复杂,因为必须注意单行可以包含多个文本编辑。
进一步的困难:未闭合的括号对
到目前为止,我们假设所有括号对都是平衡的。然而,我们也希望支持未闭合和未打开的括号对。递归下降解析器的优点在于我们可以使用锚点集来改进错误恢复。
考虑以下示例
( [1]
} [2]
) [3]
显然 [2] 处的 } 不关闭任何括号对,表示一个未打开的括号。[1] 和 [3] 处的括号很好地匹配。然而,当在文档开头插入 { 时,情况发生了变化
{ [0]
( [1]
} [2]
) [3]
现在,[0] 和 [2] 应该匹配,而 [1] 是一个未闭合的括号,[3] 是一个未打开的括号。
特别是,在下面的示例中,[1] 应该是一个在 [2] 之前终止的未闭合括号
{
( [1]
} [2]
{}
否则,打开一个括号可能会改变不相关后续括号对的嵌套级别。
为了支持这种错误恢复,可以使用锚点集来跟踪调用者可以继续使用的预期令牌集。在前面示例中位置 [1] 处的锚点集将是} } 时,它不会消耗它并返回一个未闭合的括号对。
在第一个示例中,[2] 处的锚点集是) }。因为它不属于锚点集,所以它被报告为未打开的括号。
在重用节点时需要考虑这一点:当在 ( } ) 前面加上 { 时,它不能重用。我们使用位集来编码锚点集,并为每个节点计算包含未打开括号的集合。如果它们相交,我们就不能重用该节点。幸运的是,只有少数几种括号类型,所以这对性能影响不大。
未来展望
高效的括号对颜色高亮是一个有趣的挑战。借助新的数据结构,我们还可以更有效地解决其他与括号对相关的问题,例如常规括号匹配或显示彩色行作用域。
尽管 JavaScript 可能不是编写高性能代码的最佳语言,但通过降低渐近算法复杂度可以获得很大的速度提升,尤其是在处理大型输入时。
编码愉快!
Henning Dieterichs,VS Code 团队成员 @hediet_dev