语言服务器索引格式 (LSIF)
2019 年 2 月 19 日,作者:Dirk Bäumer
无需检出(checkout)即可实现丰富的代码导航
作为一名开发人员,您会花费大量时间阅读和审查代码,而不仅仅是编写新的源代码。例如,您可能希望浏览像 GitHub 这样的仓库中的现有代码库,或者您可能想要审查同事的拉取请求(Pull Request)。
通常,您需要检出(check out)一个分支或克隆(clone)一个仓库,将源代码拉取到本地机器上,打开您首选的开发工具,然后才能开始阅读和导航代码。如果能不先克隆仓库就能做到这一点,那岂不是很酷?想象一下,无需下载源代码即可获得智能代码功能,例如悬停信息、转到定义(Go to Definition)和查找所有引用(Find All References)。博客文章《丰富代码导航体验初探》展示了拉取请求审查的这种场景。
语言服务器索引格式(LSIF,发音类似于“else if”)的目标是支持在开发工具或 Web UI 中实现丰富的代码导航,而无需本地源代码副本。该格式在精神上类似于语言服务器协议(LSP),LSP 简化了将丰富的代码编辑功能集成到开发工具中的过程。
为什么不直接使用现有的 LSP 语言服务器?LSP 提供了丰富的代码编写功能,例如自动完成、按键格式化和丰富的代码导航。为了高效地提供这些功能,语言服务器要求所有源代码文件在本地磁盘上可用。LSP 语言服务器可能还会将部分或全部文件读入内存,并计算抽象语法树来支持这些功能。语言服务器索引格式的目标是增强 LSP 协议,以在没有这些要求的情况下支持丰富的代码导航功能。LSIF 定义了一种标准格式,供语言服务器或其他编程工具发出它们对代码工作区的了解。然后,这些持久化的信息可用于回答同一工作区的 LSP 请求,而无需运行语言服务器。
语言服务器索引格式
LSIF 建立在 LSP 之上,并使用与 LSP 中定义的数据类型相同的数据类型。从高层次来看,LSIF 模拟了语言服务器请求返回的数据。与 LSP 一样,LSIF 不包含任何程序符号信息,LSIF 也不定义任何符号语义(例如,什么构成符号的定义,或者一个方法是否重写了另一个方法)。因此,LSIF 不定义符号数据库,这与 LSP 的方法一致。
使用现有的 LSP 数据类型作为 LSIF 的基础还有另一个优势,即 LSIF 可以轻松集成到已经理解 LSP 的工具或服务器中。
让我们看一个例子。我们从一个名为 sample.ts 的简单 Typescript 文件开始,其内容如下:
function bar(): void {}
在 Visual Studio Code 中将鼠标悬停在 bar() 上会显示以下悬停信息:
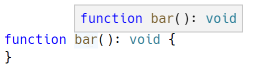
此悬停信息使用 Hover 类型在 LSP 中表示:
export interface Hover {
/**
* The hover's content
*/
contents: MarkupContent | MarkedString | MarkedString[];
/**
* An optional range
*/
range?: Range;
}
在上面的示例中,具体值是:
{
contents: [{ language: 'typescript', value: 'function bar(): void' }];
}
客户端工具将通过发送针对文档 file:///Users/username/sample.ts 中位置 {line: 0, character: 10} 的 textDocument/hover 请求,从语言服务器检索悬停内容。
LSIF 定义了一种格式,语言服务器或独立工具会发出该格式来描述元组 ['textDocument/hover', 'file:///Users/username/sample.ts', {line: 0, character: 10}] 解析为上述悬停信息。然后可以将数据获取并持久化到数据库中。
LSP 请求基于位置,但结果通常仅针对范围变化,而不是针对单个位置变化。在上面的悬停示例中,对于标识符 bar 的所有位置,悬停值都是相同的。这意味着当用户将鼠标悬停在 bar 中的 b 上或 bar 中的 r 上时,返回的悬停值相同。为了使发出的数据更紧凑,LSIF 使用范围而不是位置。对于此示例,LSIF 工具会发出元组 ['textDocument/hover', 'file:///Users/username/sample.ts', { start: { line: 0, character: 9 }, end: { line: 0, character: 12 }],其中包含范围信息。
LSIF 使用图来发出此信息。在图中,LSP 请求使用边表示。文档、范围或请求结果(例如,悬停)使用顶点表示。这种格式具有以下优点:
- 对于给定的代码范围,可以有不同的结果。对于给定的标识符范围,用户可能对悬停值、定义的a位置或查找所有引用感兴趣。因此,LSIF 将这些结果与范围链接起来。
- 通过添加新的边或顶点种类,可以轻松扩展格式以包含其他请求类型或结果。
- 一旦数据可用,就可以立即发出。这使得流式传输成为可能,而不是必须在内存中存储大量数据。例如,随着解析的进行,应该为每个文件发出数据。
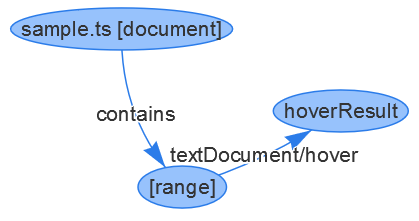
对于悬停示例,发出的 LSIF 图数据如下所示:
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the range for the identifier bar
{ id: 4, type: "vertex", label: "range", start: { line: 0, character: 9}, end: { line: 0, character: 12 } }
// an edge saying that the document with id 1 contains the range with id 4
{ id: 5, type: "edge", label: "contains", outV: 1, inV: 4}
// a vertex representing the actual hover result
{ id: 6, type: "vertex", label: "hoverResult",
result: {
contents: [
{ language: "typescript", value: "function bar(): void" }
]
}
}
// an edge linking the hover result to the range.
{ id: 7, type: "edge", label: "textDocument/hover", outV: 4, inV: 6 }
相应的图看起来像这样:
LSP 还支持仅将文档作为参数的请求(它们不基于位置)。对代码理解有用的示例请求是获取所有文档符号的列表或计算所有折叠范围。这些请求在 LSIF 中以 [request, document] -> result 的形式建模。
让我们看另一个例子:
function bar(): void {
console.log('Hello World!');
}
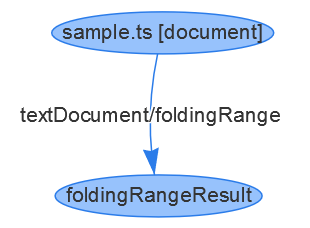
包含上述函数 bar 的文档的折叠范围结果如下所示:
// a vertex representing the document
{ id: 1, type: "vertex", label: "document", uri: "file:///Users/username/sample.ts", languageId: "typescript" }
// a vertex representing the folding result
{ id: 2, type: "vertex", label: "foldingRangeResult", result: [ { startLine: 0, startCharacter: 20, endLine: 2, endCharacter: 1 } ] }
// an edge connecting the folding result to the document.
{ id: 3, type: "edge", label: "textDocument/foldingRange", outV: 1, inV: 2 }
这些只是 LSIF 支持的 LSP 请求的两个示例。当前版本的 LSIF 规范还支持文档符号、文档链接、转到定义、转到声明、转到类型定义、查找所有引用和转到实现。
我们需要您的反馈!
我们在 LSIF 规范上取得了良好的初步进展,我们希望向社区开放讨论,以便您了解我们正在进行的工作。如需反馈,请在问题 Language Server Index Format 中发表评论。
如何开始
要开始使用 LSIF,您可以查看以下资源:
- LSIF 规范 - 该文档还描述了一些为保持发出数据紧凑而进行的其他优化。
- TypeScript 的 LSIF 索引 - 一个为 TypeScript 生成 LSIF 的工具。README 提供了使用该工具的说明。
- Visual Studio Code LSIF 扩展 - 一个用于 VS Code 的扩展,它使用 LSIF JSON 转储提供语言理解功能。如果您实现了一个新的 LSIF 生成器,您可以使用此扩展来使用任意源代码对其进行验证。