通过名称重整缩小 VS Code
2023 年 7 月 20 日,作者:Matt Bierner,@mattbierner
我们最近将 Visual Studio Code 发布版 JavaScript 的大小减少了 20%。这相当于节省了 3.9 MB 多一点。当然,这比我们发布说明中一些单独的 GIF 还要小,但这仍然不容小觑!这种减少不仅意味着需要下载和存储在磁盘上的代码更少,它还改善了启动时间,因为在运行 JavaScript 之前需要扫描的源代码更少。考虑到我们没有删除任何代码,也没有对代码库进行任何重大重构就实现了这一缩减,这还算不错。相反,所有这一切都只需要一个新的构建步骤:名称混淆 (name mangling)。
在这篇文章中,我想分享我们如何识别这个优化机会,探索解决问题的方法,并最终实现了 20% 的大小缩减。我更想把它作为一个案例研究,说明我们 VS Code 团队如何处理工程问题,而不是专注于混淆的具体细节。名称混淆是一个巧妙的技巧,但在许多代码库中可能不值得,而且我们特定的混淆方法很可能可以改进(或者根本不需要,这取决于您的项目是如何构建的)。
发现问题
VS Code 团队对性能充满热情,无论是优化热门代码路径、减少 UI 重布局,还是加快启动时间。这种热情包括保持 VS Code JavaScript 的小尺寸。随着 VS Code 除了桌面应用程序之外还在 Web 端 (https://vscode.dev) 发布,代码大小变得更加受关注。积极监控代码大小使 VS Code 团队成员能够及时了解其变化。
不幸的是,这些变化几乎总是增长。尽管我们对 VS Code 中构建了哪些功能进行了大量思考,但多年来添加新功能必然会增加我们发布的代码量。例如,VS Code 的一个核心 JavaScript 文件(workbench.js)现在大约是八年前的四倍大。现在,如果您考虑到八年前 VS Code 缺少许多人今天认为必不可少的功能——例如编辑器选项卡或内置终端——这种增长可能不像听起来那么糟糕,但也不是一无是处。
4 倍的大小增长也是在经过大量持续的性能工程工作之后。同样,这项工作之所以发生,很大程度上是因为我们持续跟踪代码大小,并且非常不喜欢看到它增加。我们已经完成了许多简单的代码大小优化,包括通过 esbuild 运行我们的代码进行压缩。多年来,寻找进一步的节省变得越来越具有挑战性。许多潜在的节省也不值得它们引入的风险,或者实施和维护它们所需的额外工程工作。这意味着我们不得不眼睁睁看着我们的 JavaScript 大小慢慢增加。
然而,去年在 vscode.dev 上调试我们压缩后的源代码时,我注意到了一些令人惊讶的事情:我们压缩后的 JavaScript 仍然包含大量长标识符名称,例如 extensionIgnoredRecommendationsService。这让我感到惊讶。我原以为 esbuild 已经缩短了这些标识符。事实证明,esbuild 确实通过一个名为“混淆 (mangling)”的过程在某些情况下缩短了标识符(这个术语 JavaScript 工具可能借鉴了 编译语言中一个大致相似的过程)。
在压缩过程中,混淆会缩短长标识符名称,将代码从
const someLongVariableName = 123;
console.log(someLongVariableName);
变为短得多的
const x = 123;
console.log(x);
由于 JavaScript 以源文本的形式发布,缩短标识符名称的长度实际上会减小程序的大小。我知道如果你是来自编译语言,这种优化可能看起来有点傻,但在 JavaScript 这个美妙的世界里,我们乐于接受任何能找到的胜利!
现在,在您急于将所有变量重命名为单个字母之前,我想强调一点,这种优化需要谨慎对待。如果潜在的优化使您的源代码可读性或可维护性降低,或者需要大量的体力劳动,那么它几乎不值得,除非它能带来真正惊人的改进。这里那里节省几个字节固然不错,但远算不上惊人。
如果我们可以免费获得这样的出色优化,例如通过我们的构建工具自动完成,那么这种计算就会改变。事实上,像 esbuild 这样的智能工具已经实现了标识符混淆。这意味着我们可以继续编写我们的 veryLongAndDescriptiveNamesThatWouldMakeEvenObjectiveCProgrammersBlush,然后让我们的构建工具为我们缩短它们!
尽管 esbuild 实现了混淆,但默认情况下,它只在确信混淆不会改变代码行为时才混淆名称。毕竟,打包器破坏你的代码真的很难受。实际上,这意味着 esbuild 会混淆局部变量名和参数名。这是安全的,除非你的代码在做一些真正荒谬的事情(在这种情况下,你可能面临比代码大小更大的问题)。
然而,esbuild 的保守方法意味着它会跳过混淆许多名称,因为它不能确定更改它们是安全的。作为一个简单地说明问题可能出在哪里,请考虑以下代码:
const obj = { longPropertyName: 123 };
function lookup(prop) {
return obj[prop];
}
console.log(lookup('longPropertyName'));
如果混淆将 longPropertyName 更改为 x,则下一行的动态查找将不再起作用
const obj = { x: 123 }; // Here `longPropertyName` gets rewritten to `x`
function lookup(prop) {
return obj[prop];
}
console.log(lookup('longPropertyName')); // But this reference doesn't and now the lookup is broken
请注意上面的代码,即使属性本身在混淆过程中已更改,我们仍然尝试使用 longPropertyName 来访问该属性。
虽然这个例子是人为设计的,但在真实代码中实际上有很多方法会导致这些中断
- 动态属性访问。
- 序列化对象或将 JSON 解析为预期的对象形状。
- 你公开的 API(消费者将不知道新的混淆名称)。
- 你消费的 API(包括 DOM API)。
尽管您可以强制 esbuild 混淆它找到的几乎所有名称,但由于上述原因,这样做会完全破坏 VS Code。
尽管如此,我仍然无法摆脱这样的感觉:我们必须能够在 VS Code 代码库中做得更好。如果我们不能混淆每个名称,也许我们至少可以找到一些我们可以安全地混淆的名称子集。
私有属性的错误尝试
回过头来看我们压缩后的源代码,另一件让我眼前一亮的事情是,我看到了多少以 _ 开头的长名称。按照惯例,这表示一个私有属性。私有属性当然可以安全地混淆,而且类外部的代码对此一无所知,对吧?等等,esbuild 不应该已经为我们做这件事了吗?然而我知道编写 esbuild 的人可不是省油的灯。如果 esbuild 没有混淆私有属性,那几乎肯定是有充分理由的。
随着我对这个问题的深入思考,我意识到私有属性受到与上面 longPropertyName 示例中所示的相同动态属性查找问题的影响。我确信像你这样聪明的 TypeScript 程序员绝不会编写这样的代码,但动态模式在实际代码库中足够常见,以至于 esbuild 选择采取安全措施。
还要记住,TypeScript 中的 private 关键字实际上只是一个礼貌的建议。当 TypeScript 代码编译成 JavaScript 时,private 关键字基本上被删除了。这意味着没有任何东西可以阻止类外部的粗鲁代码随意访问私有属性
class Foo {
private bar = 123;
}
const foo: any = new Foo();
console.log(foo.bar);
希望您的代码不会直接做这种可疑的事情,但粗心大意地更改属性名称可能会以许多有趣且意想不到的方式困扰您,例如对象展开、序列化以及当不同类共享相同的属性名称时。
幸运的是,我意识到对于 VS Code,我有一个巨大的优势:我正在处理一个(大部分)健全的代码库。我可以做出许多 esbuild 无法做出的假设,例如没有动态私有属性访问或错误的 any 访问。这进一步简化了我面临的问题。
因此,我和 Johannes Rieken (@johannesrieken) 开始探索私有属性混淆。我们的第一个想法是尝试在代码库中普遍采用 JavaScript 的原生 #private 字段。私有字段不仅不受上述所有问题的影响,而且它们已经由 esbuild 自动混淆。更接近纯粹的 JavaScript 也很有吸引力。
然而,我们很快就放弃了这种方法,因为它需要大量的(意味着有风险的)代码更改,包括删除我们所有对 参数属性 的使用。作为相对较新的功能,私有字段也尚未在所有运行时中进行优化。使用它们可能会导致从可忽略不计到 大约 95% 的减速!尽管从长远来看这可能是正确的更改,但这不是我们现在需要的。
接下来我们发现 esbuild 可以选择性地混淆与给定正则表达式匹配的属性。然而,这个正则表达式只匹配标识符名称。这意味着我们无法知道该属性是否在 TypeScript 中声明为 private,但我们可以尝试混淆所有以 _ 开头的属性,我们希望这只包括私有和受保护的属性。
很快,我们就有了一个将所有 _ 属性混淆的工作构建。不错!这证明了私有属性混淆是可行的,并且带来了一些不错的节省,尽管远低于我们所希望的。
不幸的是,仅基于名称的混淆有一些严重的缺点,包括要求我们代码库中的所有私有属性都以 _ 开头。VS Code 代码库并不始终遵循这种命名约定,而且在少数地方,我们也有以 _ 开头的公共属性(通常在属性需要在外部访问但不应被视为 API 的情况下,例如在测试中)。
我们也不完全相信混淆后的代码实际上是正确的。当然,我们可以运行我们的测试或尝试启动 VS Code,但这很耗时,而且如果我们忽略了不常见的代码路径怎么办?我们不能百分之百确定我们只混淆了私有属性而没有触及其他代码。这种方法似乎既有风险又难以采用。
使用 TypeScript 自信地进行混淆
在思考如何才能更自信地进行混淆构建步骤时,我们有了一个新想法:如果 TypeScript 可以为我们验证混淆后的代码呢?就像 TypeScript 可以在正常代码中捕获未知属性访问一样,TypeScript 编译器应该能够捕获属性已被混淆但对其引用未正确更新的情况。我们不必混淆编译后的 JavaScript,而是可以混淆我们的 TypeScript 源代码,然后用混淆后的标识符名称编译新的 TypeScript。对混淆后的源代码进行编译步骤将使我们对没有意外破坏代码更有信心。
不仅如此,通过使用 TypeScript,我们可以真正找到所有 private 属性(而不是那些碰巧以 _ 开头的属性)。我们甚至可以使用 TypeScript 现有的 rename 功能来智能地重命名符号,而不会以意想不到的方式改变对象形状。
急于尝试这种新方法,我们很快就想出了一个新的混淆构建步骤,它大致是这样的
for each private or protected property in codebase (found using TypeScript's AST):
if the property should be mangled:
Compute a new name by looking for an unused symbol name
Use TypeScript to generate a rename edit for all references to the property
Apply all rename edits to our typescript source
Compile the new edited TypeScript sources with the mangled names
令人有些惊讶的是,对于这种看似幼稚的方法,它奏效了!嗯,至少大部分奏效了。
虽然 TypeScript 在我们的整个代码库中生成了成千上万个正确的编辑,这确实给我们留下了深刻的印象,但我们也不得不添加逻辑来处理一些极端情况
-
新的私有属性名称不仅要在当前类中唯一,还必须在当前类的所有超类和子类中唯一。根源再次是 TypeScript 的
private关键字只是一个编译时装饰,它实际上并不强制超类和子类不能访问私有属性。如果不小心,重命名可能会引入名称冲突(幸运的是 TypeScript 会将这些报告为错误)。 -
在我们的代码中,有几个地方子类将继承的受保护属性公开。虽然其中许多是错误,但我们还添加了代码来在这些情况下禁用混淆。
在为这些情况添加代码后,我们很快就有了可用的构建。通过混淆私有属性,VS Code 的主 workbench.js 脚本的大小从 12.3 MB 变为 10.6 MB,减少了近 14%。这也带来了 5% 的代码加载速度提升,因为需要扫描的源文本更少。考虑到除了对源代码中一些不安全模式的少量非常小的修复之外,这些节省基本上是免费的,这根本不算坏。
经验教训和进一步工作
混淆私有属性表明,在不进行大规模代码更改或昂贵重写的情况下,VS Code 仍然可以实现显著改进。在这种情况下,我怀疑多年来其他人曾查看过 VS Code 的压缩源代码,并对那些长名称感到疑惑。然而,解决这个问题可能看起来无法安全地完成,或者可能只是不值得投入大量工程资源。
我们这次成功的关键是识别出一种情况(私有属性),在这种情况下,名称混淆可能是安全的,并且优化仍然会带来显著的改进。然后我们考虑如何尽可能安全地进行这种更改。这意味着首先使用 TypeScript 的工具自信地重命名标识符,然后再次使用 TypeScript 确保我们新混淆的源代码仍然可以正确编译。在此过程中,我们的代码已经遵循了大多数 TypeScript 最佳实践,并且也有测试覆盖了许多常见的 VS Code 代码路径,这极大地帮助了我们。所有这些结合在一起,使得 Joh 和我可以在业余时间进行工作,交付一个相当大的更改,而对在 VS Code 上工作的其他开发人员几乎没有影响。
然而,混淆的故事还没有结束。浏览我们新混淆和压缩的源代码,我沮丧地看到了 provideWorkspaceTrustExtensionProposals 和许多其他冗长的名称。最值得注意的是,localize(我们用于 UI 中显示的字符串的函数)出现了近 5000 次。显然,还有改进的空间。
使用与混淆私有属性相同的 approach 和 techniques,我很快又发现了一个常见的代码模式,我们可以安全地混淆它,并获得高投资回报:导出的符号名称。只要这些导出只在内部使用,我就相信我们可以缩短它们而不会改变代码的行为。
这在很大程度上被证明是正确的,尽管又出现了一些并发症。例如,我们必须确保不会意外触及扩展使用的 API,并且还必须豁免一些从 TypeScript 导出但随后从无类型 JavaScript 调用(通常这些是工作线程或进程的入口点)的符号。
导出混淆工作已于上个迭代发布,进一步将 workbench.js 的大小从 10.6 MB 减少到 9.8 MB。所有这些减少总计,该文件现在比未混淆时小 20%。在所有 VS Code 中,混淆从我们编译后的源代码中移除了 3.9 MB 的 JavaScript 代码。这不仅大大减少了下载大小和安装大小,而且每次启动 VS Code 时,需要扫描的 JavaScript 也减少了 3.9 MB。
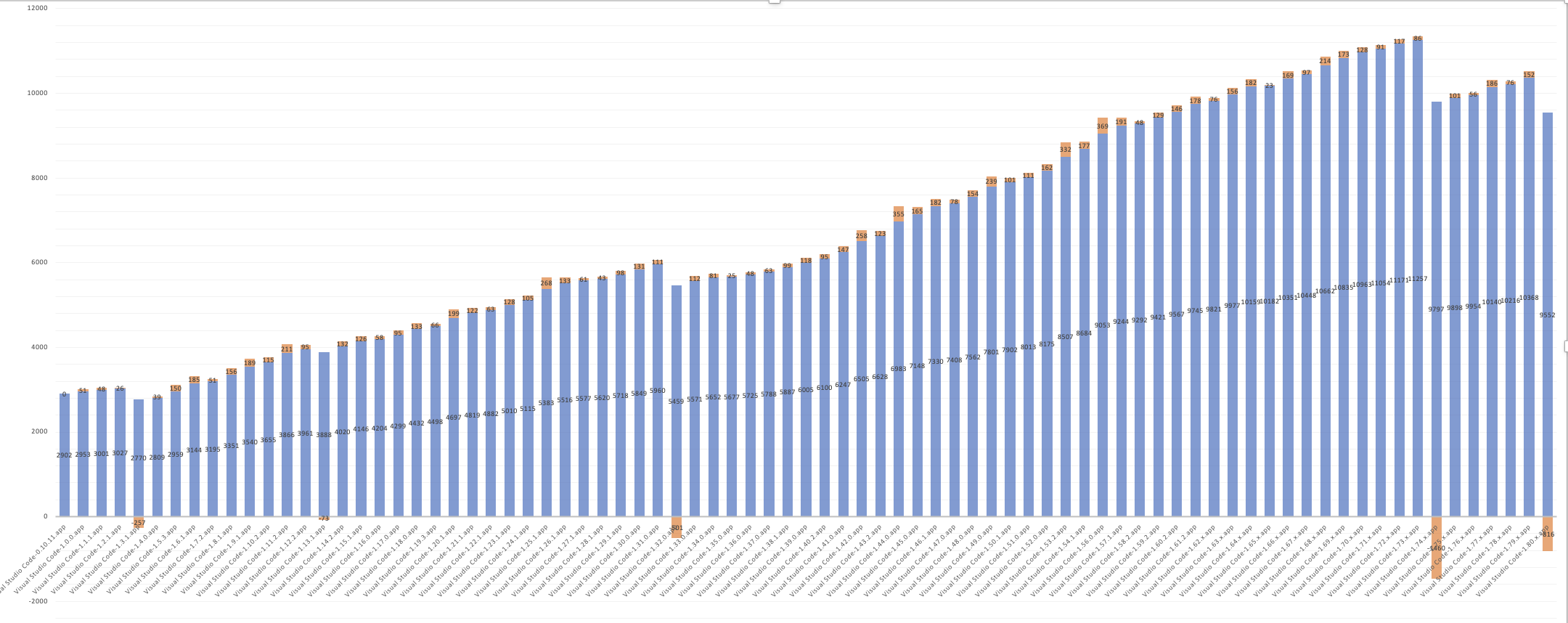
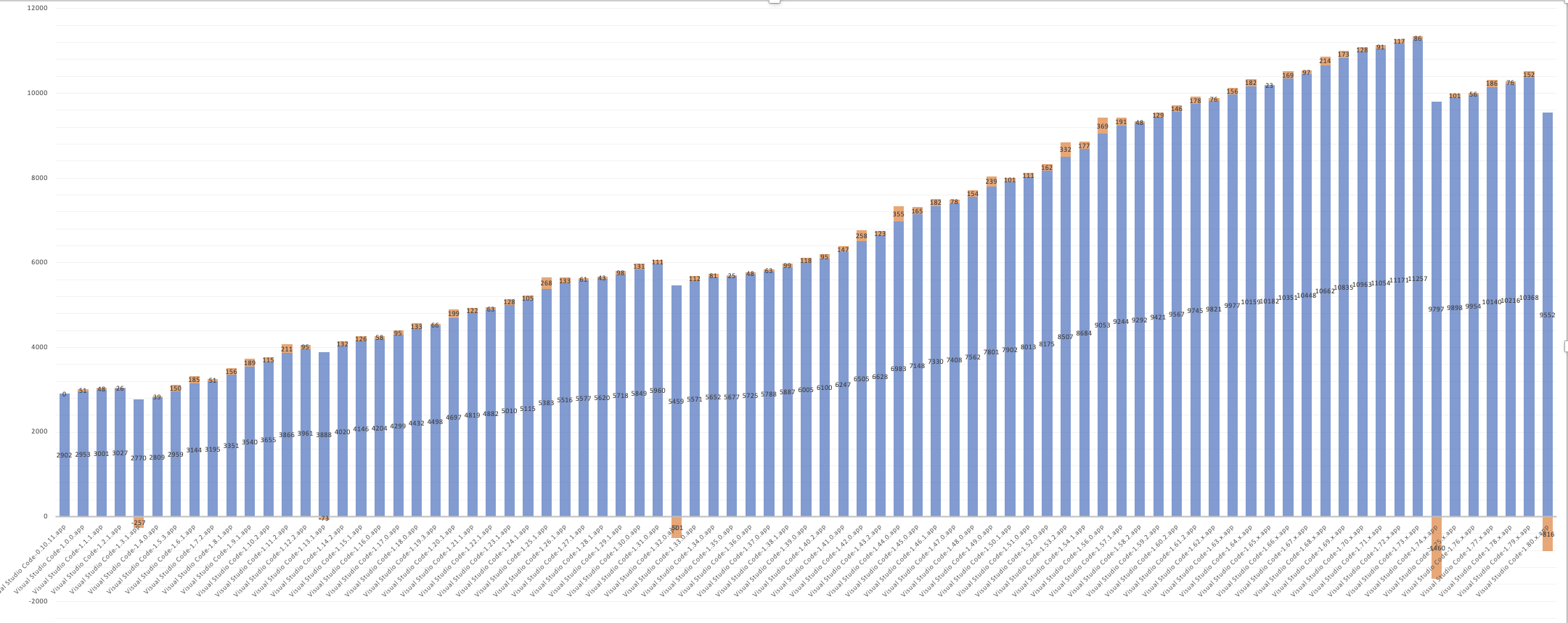
此图表显示了 workbench.js 随时间变化的大小。请注意右侧的两个下降。VS Code 1.74 中的第一次大幅下降是混淆私有属性的结果。1.80 中第二次较小的下降是由于混淆导出。

我们的混淆实现无疑可以改进,因为我们压缩后的源代码仍然包含许多长名称。如果这样做值得,并且我们能想出一种安全的方法,我们可能会进一步调查这些。理想情况下,总有一天这项工作中的大部分将不再需要。原生私有属性已经自动混淆,我们的构建工具也有望在整个代码库中更好地优化代码。您可以查看我们当前的 混淆实现。
我们一直在努力使 VS Code 和我们的代码库变得更好,我认为混淆工作很好地展示了我们如何处理这个问题。优化是一个持续的过程,而不是一次性的事情。通过持续监控我们的代码大小,我们了解了它随时间的变化。这种意识无疑有助于防止我们的代码大小进一步膨胀,也鼓励我们始终寻求改进。尽管混淆是一种看似有吸引力的技术,但它最初风险太大,不值得认真考虑。只有当我们努力降低风险、创建正确的安全网,并使采用混淆的成本几乎为零时,我们才最终有足够的信心在我们的构建中启用它。我对最终结果感到非常自豪,也对我们实现它的方式感到同样自豪。
编程愉快,
Matt Bierner,VS Code 团队成员 @mattbierner
感谢 Johannes Rieken 在实现混淆方面的关键工作,感谢 TypeScript 团队构建了让我们能够安全地实现混淆的工具,感谢 esbuild 提供了其极速的打包器,感谢整个 VS Code 团队构建了一个适合此类优化的代码库。最后但同样重要的是,非常感谢 V8 团队和所有其他 JS 引擎,尽管我们向他们扔去了大量 horribly mangled 的 JavaScript,他们总是让我们看起来很快。