语法高亮优化
2017年2月8日 - Alexandru Dima
Visual Studio Code 1.9版包含我们一直在努力的一个很酷的性能改进,我想讲述它的故事。
一句话总结:TextMate 主题在 VS Code 1.9 中将更符合作者的意图,同时渲染速度更快,内存消耗更少。
语法高亮
语法高亮通常包括两个阶段。首先,将令牌(token)分配给源代码,然后,这些令牌会被主题(theme)瞄准,分配颜色,然后,你的源代码就以颜色渲染出来了。这是将文本编辑器变成代码编辑器的唯一功能。
VS Code(以及 Monaco 编辑器)中的令牌化(Tokenization)逐行、从上到下、单次运行。令牌化器(tokenizer)可以在令牌化行的末尾存储一些状态,这些状态将在令牌化下一行时传递回去。这是许多令牌化引擎(包括 TextMate 语法)使用的一种技术,它允许编辑器在用户进行编辑时仅重新令牌化行的一小部分。
大多数情况下,在某行输入只会导致该行重新令牌化,因为令牌化器会返回相同的结束状态,并且编辑器可以假设后续行不会获得新的令牌。
在更罕见的情况下,在某行输入会导致当前行及其下面的一些行重新令牌化/重新绘制(直到遇到相同的结束状态)。
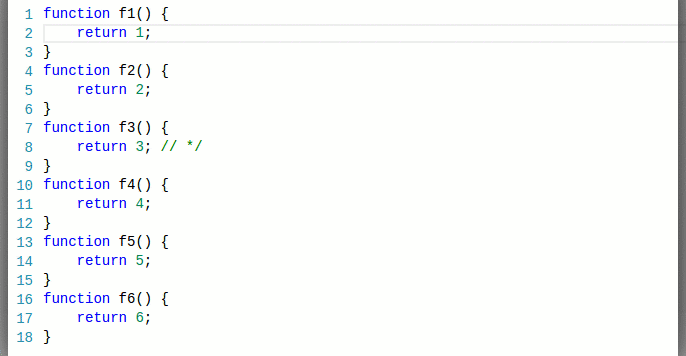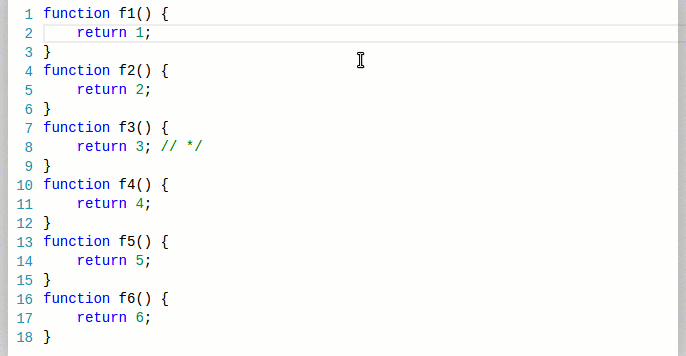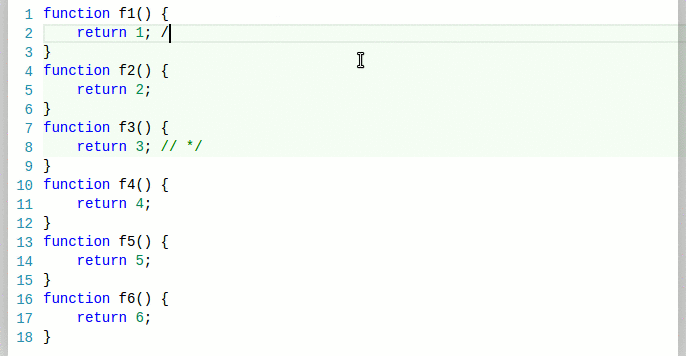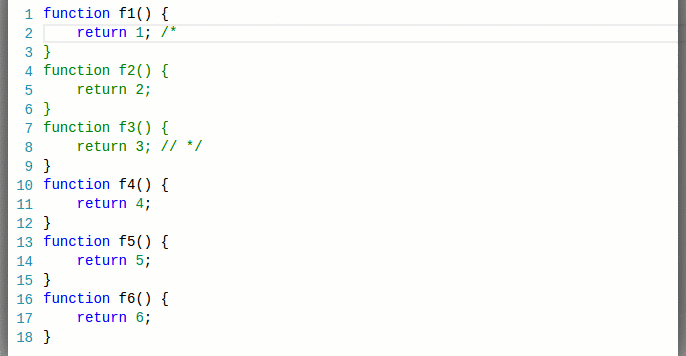
我们过去如何表示令牌
VS Code 编辑器的代码早在 VS Code 存在之前就已经编写。它以 Monaco 编辑器 的形式在各种 Microsoft 项目(包括 Internet Explorer 的 F12 工具)中发布。我们的一项要求是减少内存使用。
过去,我们手动编写令牌化器(即使是今天,在浏览器中解释 TextMate 语法也没有可行的方法,但这又是另一个故事)。对于下面这一行,我们将从我们手写的令牌化器中获得以下令牌:
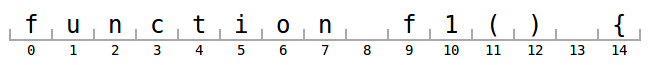
tokens = [
{ startIndex: 0, type: 'keyword.js' },
{ startIndex: 8, type: '' },
{ startIndex: 9, type: 'identifier.js' },
{ startIndex: 11, type: 'delimiter.paren.js' },
{ startIndex: 12, type: 'delimiter.paren.js' },
{ startIndex: 13, type: '' },
{ startIndex: 14, type: 'delimiter.curly.js' }
];
保留这个令牌数组在 Chrome 中占用 648 字节,因此存储这样一个对象在内存方面相当昂贵(每个对象实例必须为指向其原型、属性列表等保留空间)。我们当前的机器确实有很多 RAM,但为 15 个字符的行存储 648 字节是不可接受的。
因此,当时我们想出了一种二进制格式来存储令牌,这种格式一直使用到 VS Code 1.8(包括 1.8)。鉴于会存在重复的令牌类型,我们将其收集到一个单独的映射(按文件)中,做类似以下的事情:
// 0 1 2 3 4
map = ['', 'keyword.js', 'identifier.js', 'delimiter.paren.js', 'delimiter.curly.js'];
tokens = [
{ startIndex: 0, type: 1 },
{ startIndex: 8, type: 0 },
{ startIndex: 9, type: 2 },
{ startIndex: 11, type: 3 },
{ startIndex: 12, type: 3 },
{ startIndex: 13, type: 0 },
{ startIndex: 14, type: 4 }
];
然后我们将 `startIndex`(32 位)和 `type`(16 位)编码为 JavaScript 数字的 53 位尾数 中的 48 位。我们的令牌数组最终将如下所示,并且映射数组将重复用于整个文件:
tokens = [
// type startIndex
4294967296, // 0000000000000001 00000000000000000000000000000000
8, // 0000000000000000 00000000000000000000000000001000
8589934601, // 0000000000000010 00000000000000000000000000001001
12884901899, // 0000000000000011 00000000000000000000000000001011
12884901900, // 0000000000000011 00000000000000000000000000001100
13, // 0000000000000000 00000000000000000000000000001101
17179869198 // 0000000000000100 00000000000000000000000000001110
];
保留这个令牌数组在 Chrome 中占用 104 字节。元素本身应该只占用 56 字节(7 个 64 位数字),其余部分可能由 v8 存储数组的其他元数据,或者可能以 2 的幂次方分配后备存储来解释。然而,内存节省是显而易见的,并且每行令牌越多,节省越多。我们对这种方法很满意,并且从那时起一直使用这种表示方式。
注意:可能有更紧凑的存储令牌的方式,但以二分搜索的线性格式存储它们在内存使用和访问性能方面提供了最佳权衡。
令牌 <-> 主题匹配
我们认为遵循浏览器最佳实践是个好主意,例如将样式留给 CSS,因此在渲染上述行时,我们将使用 `map` 解码二进制令牌,然后使用令牌类型进行渲染,如下所示:
<span class="token keyword js">function</span>
<span class="token"> </span>
<span class="token identifier js">f1</span>
<span class="token delimiter paren js">(</span>
<span class="token delimiter paren js">)</span>
<span class="token"> </span>
<span class="token delimiter curly js">{</span>
我们将 在 CSS 中 编写我们的主题(例如 Visual Studio 主题):
...
.monaco-editor.vs .token.delimiter { color: #000000; }
.monaco-editor.vs .token.keyword { color: #0000FF; }
.monaco-editor.vs .token.keyword.flow { color: #AF00DB; }
...
结果相当不错,我们可以在某个地方翻转一个类名,并立即将新主题应用到编辑器。
TextMate 语法
在 VS Code 发布时,我们有大约 10 个手写的令牌化器,主要用于 Web 语言,这对于一个通用桌面代码编辑器来说绝对不够。于是引入了 TextMate 语法,它是一种描述性地指定令牌化规则的形式,已被众多编辑器采用。不过有一个问题,TextMate 语法与我们手写的令牌化器工作方式不太一样。
TextMate 语法,通过使用 begin/end 状态或 while 状态,可以推入跨越多个令牌的作用域。下面是使用 JavaScript TextMate 语法(为简洁起见忽略空白)的相同示例:

VS Code 1.8 中的 TextMate 语法
如果我们对作用域栈进行剖析,每个令牌基本上都会得到一个作用域名称数组,我们将从令牌化器中得到类似以下内容:
tokens = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
所有的令牌类型都是字符串,我们的代码还没有准备好处理字符串数组,更不用说对令牌的二进制编码的影响了。因此,我们按照以下策略将作用域数组“近似”*为一个字符串:
- 忽略最不具体的范围(即
source.js);它很少增加任何价值。 - 将每个剩余的范围按
"."分割。 - 去除重复的唯一片段。
- 使用稳定的排序函数对剩余片段进行排序(不一定是按字母顺序排序)。
- 将片段按
"."连接起来。
tokens = [
{ startIndex: 0, type: 'meta.function.js.storage.type' },
{ startIndex: 9, type: 'meta.function.js' },
{ startIndex: 9, type: 'meta.function.js.definition.entity.name' },
{ startIndex: 11, type: 'meta.function.js.definition.parameters.punctuation' },
{ startIndex: 13, type: 'meta.function.js' },
{ startIndex: 14, type: 'meta.function.js.definition.punctuation.block' }
];
*: 我们所做的是完全错误的,“近似”是一个非常客气的说法 :)
这些令牌然后会“适应”并遵循与手动编写的令牌化器相同的代码路径(获得二进制编码),然后也会以相同的方式渲染
<span class="token meta function js storage type">function</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition entity name">f1</span>
<span class="token meta function js definition parameters punctuation">()</span>
<span class="token meta function js"> </span>
<span class="token meta function js definition punctuation block">{</span>
TextMate 主题
TextMate 主题通过 范围选择器 工作,这些选择器选择具有特定范围的令牌并对其应用主题信息,例如颜色、粗体等。
给定具有以下范围的令牌:
// C B A
scopes = ['source.js', 'meta.definition.function.js', 'entity.name.function.js'];
以下是一些将匹配的简单选择器,按其排名(降序)排序:
| 选择器 | C | B | A |
|---|---|---|---|
| source | source.js | meta.definition.function.js | entity.name.function.js |
| source.js | source.js | meta.definition.function.js | entity.name.function.js |
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name.function.js | source.js | meta.definition.function.js | entity.name.function.js |
观察:
entity胜过meta.definition.function,因为它匹配一个更具体的范围(A胜过B)。
观察:`entity.name` 胜过 `entity`,因为它们都匹配相同的范围 (`A`),但 `entity.name` 比 `entity` 更具体。
父选择器
为了使事情变得复杂一点,TextMate 主题还支持父选择器。以下是一些使用简单选择器和父选择器的示例(再次按其排名降序排序):
| 选择器 | C | B | A |
|---|---|---|---|
| meta | source.js | meta.definition.function.js | entity.name.function.js |
| source meta | source.js | meta.definition.function.js | entity.name.function.js |
| source.js meta | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| source meta.definition | source.js | meta.definition.function.js | entity.name.function.js |
| entity | source.js | meta.definition.function.js | entity.name.function.js |
| source entity | source.js | meta.definition.function.js | entity.name.function.js |
| meta.definition entity | source.js | meta.definition.function.js | entity.name.function.js |
| entity.name | source.js | meta.definition.function.js | entity.name.function.js |
| source entity.name | source.js | meta.definition.function.js | entity.name.function.js |
观察:
source entity胜过entity,因为它们都匹配相同的范围(A),但source entity也匹配父范围(C)。
观察:`entity.name` 胜过 `source entity`,因为它们都匹配相同的范围 (`A`),但 `entity.name` 比 `entity` 更具体。
注意:还有第三种选择器,涉及排除范围,我们在此不讨论。我们没有为此类选择器添加支持,并且我们注意到它在实际中很少使用。
VS Code 1.8 中的 TextMate 主题
以下是两个 Monokai 主题规则(为简洁起见此处以 JSON 格式表示;原始格式为 XML):
...
// Function name
{ "scope": "entity.name.function", "fontStyle": "", "foreground":"#A6E22E" }
...
// Class name
{ "scope": "entity.name.class", "fontStyle": "underline", "foreground":"#A6E22E" }
...
在 VS Code 1.8 中,为了匹配我们的“近似”范围,我们会生成以下动态 CSS 规则:
...
/* Function name */
.entity.name.function { color: #A6E22E; }
...
/* Class name */
.entity.name.class { color: #A6E22E; text-decoration: underline; }
...
然后我们会把“近似”范围和“近似”规则的匹配留给 CSS。但是 CSS 的匹配规则与 TextMate 选择器的匹配规则不同,尤其是在排名方面。CSS 排名是基于匹配的类名数量,而 TextMate 选择器排名有明确的范围特异性规则。
这就是为什么 VS Code 中的 TextMate 主题看起来还行,但从未完全符合作者的意图。有时,差异会很小,但有时这些差异会完全改变主题的感受。
一些机缘巧合
随着时间的推移,我们已经逐步淘汰了手写的令牌化器(最后一个是 HTML 的,仅在几个月前)。因此,在今天的 VS Code 中,所有文件都使用 TextMate 语法进行令牌化。对于 Monaco 编辑器,我们已经迁移到使用 Monarch(一种描述性令牌化引擎,本质上与 TextMate 语法相似,但表达力更强,并且可以在浏览器中运行)来支持大多数语言,并且我们添加了一个用于手动令牌化器的包装器。总而言之,这意味着支持一种新的令牌化格式将需要更改 3 个令牌提供程序(TextMate、Monarch 和手动包装器),而不是 10 个以上。
几个月前,我们审查了 VS Code 核心中所有读取令牌类型的代码,我们注意到这些消费者只关心字符串、正则表达式或注释。例如,括号匹配逻辑会忽略包含范围 "string"、"comment" 或 "regex" 的令牌。
最近,我们得到了内部合作伙伴(Microsoft 内部其他使用 Monaco Editor 的团队)的同意,他们不再需要在 Monaco Editor 中支持 IE9 和 IE10。
可能最重要的是,编辑器最受投票的功能是 minimap 支持。为了在合理的时间内渲染minimap,我们不能使用 DOM 节点和 CSS 匹配。我们可能会使用 canvas,并且我们需要在 JavaScript 中知道每个令牌的颜色,以便可以用正确的颜色绘制那些微小的字母。
也许我们最大的突破是,我们不需要存储令牌,也不需要存储它们的范围,因为令牌只在主题匹配它们或括号匹配跳过字符串方面产生影响。
最后,VS Code 1.9 中的新功能
表示 TextMate 主题
下面是一个非常简单的主题可能的样子:
theme = [
{ "foreground": "#F8F8F2" },
{ "scope": "var", "foreground": "#F8F8F2" },
{ "scope": "var.identifier", "foreground": "#00FF00", "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": "#0000FF" },
{ "scope": "constant", "foreground": "#100000", "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": "#200000" },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": "#300000" },
];
加载时,我们将为主题中出现的每种唯一颜色生成一个 ID,并将其存储到颜色映射中(类似于我们上面对令牌类型所做的那样)。
// 1 2 3 4 5 6
colorMap = ["reserved", "#F8F8F2", "#00FF00", "#0000FF", "#100000", "#200000", "#300000"]
theme = [
{ "foreground": 1 },
{ "scope": "var", "foreground": 1, },
{ "scope": "var.identifier", "foreground": 2, "fontStyle": "bold" },
{ "scope": "meta var.identifier", "foreground": 3 },
{ "scope": "constant", "foreground": 4, "fontStyle": "italic" },
{ "scope": "constant.numeric", "foreground": 5 },
{ "scope": "constant.numeric.hex", "fontStyle": "bold" },
{ "scope": "constant.numeric.oct", "fontStyle": "underline" },
{ "scope": "constant.numeric.dec", "foreground": 6 },
];
然后,我们将根据主题规则生成一个 Trie 数据结构,其中每个节点都保存着已解析的主题选项。
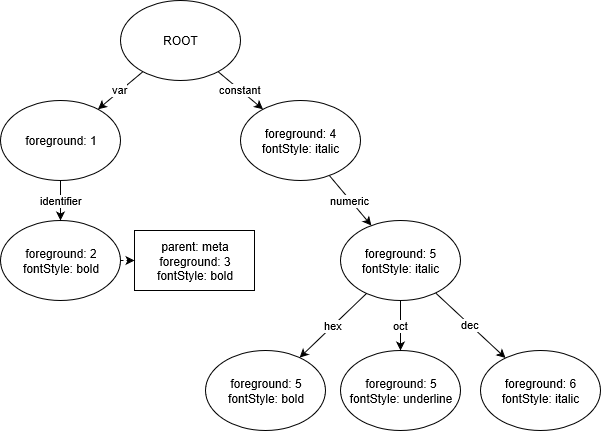
观察:
constant.numeric.hex和constant.numeric.oct的节点包含将前景色更改为5的指令,因为它们继承了constant.numeric的此指令。
观察:`var.identifier` 节点保留了额外的父规则 `meta var.identifier`,并将相应地回答查询。
当我们想知道一个范围应该如何主题化时,我们可以查询这个 Trie。
例如
| 查询 | 结果 |
|---|---|
| constant | 将前景色设置为 4,字体样式设置为 斜体 |
| constant.numeric | 将前景色设置为 5,字体样式设置为 斜体 |
| constant.numeric.hex | 将前景色设置为 5,字体样式设置为 粗体 |
| var | 将前景色设置为 1 |
| var.baz | 将前景色设置为 1(匹配 var) |
| baz | 不执行任何操作(不匹配) |
| var.identifier | 如果存在父作用域 meta,则将前景色设置为 3,字体样式设置为 粗体, 否则,将前景色设置为 2,字体样式设置为 粗体 |
令牌化的改变
VS Code 中使用的所有 TextMate 令牌化代码都位于一个单独的项目 vscode-textmate 中,该项目可以独立于 VS Code 使用。我们更改了在 vscode-textmate 中表示作用域栈的方式,使其成为 一个不可变链表,该链表也存储完全解析的 metadata。
当我们将新范围推入范围栈时,我们将在主题 Trie 中查找新范围。然后,我们可以根据从范围栈继承的内容和主题 Trie 返回的内容,立即计算出范围列表完全解析的所需前景色或字体样式。
一些示例
| 作用域栈 | 元数据 |
|---|---|
| ["source.js"] | 前景色为 1,字体样式为常规(无作用域选择器的默认规则) |
| ["source.js","constant"] | 前景色为 4,字体样式为 斜体 |
| ["source.js","constant","baz"] | 前景色为 4,字体样式为 斜体 |
| ["source.js","var.identifier"] | 前景色为 2,字体样式为 粗体 |
| ["source.js","meta","var.identifier"] | 前景色为 3,字体样式为 粗体 |
从作用域栈中弹出时,无需进行任何计算,因为我们可以直接使用存储在先前作用域列表元素中的元数据。
以下是表示作用域列表中元素的 TypeScript 类:
export class ScopeListElement {
public readonly parent: ScopeListElement;
public readonly scope: string;
public readonly metadata: number;
...
}
我们存储 32 位元数据
/**
* - -------------------------------------------
* 3322 2222 2222 1111 1111 1100 0000 0000
* 1098 7654 3210 9876 5432 1098 7654 3210
* - -------------------------------------------
* xxxx xxxx xxxx xxxx xxxx xxxx xxxx xxxx
* bbbb bbbb bfff ffff ffFF FTTT LLLL LLLL
* - -------------------------------------------
* - L = LanguageId (8 bits)
* - T = StandardTokenType (3 bits)
* - F = FontStyle (3 bits)
* - f = foreground color (9 bits)
* - b = background color (9 bits)
*/
最后,不再从令牌化引擎以对象形式发出令牌,
// These are generated using the Monokai theme.
tokens_before = [
{ startIndex: 0, scopes: ['source.js', 'meta.function.js', 'storage.type.function.js'] },
{ startIndex: 8, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 9,
scopes: [
'source.js',
'meta.function.js',
'meta.definition.function.js',
'entity.name.function.js'
]
},
{
startIndex: 11,
scopes: [
'source.js',
'meta.function.js',
'meta.parameters.js',
'punctuation.definition.parameters.js'
]
},
{ startIndex: 13, scopes: ['source.js', 'meta.function.js'] },
{
startIndex: 14,
scopes: [
'source.js',
'meta.function.js',
'meta.block.js',
'punctuation.definition.block.js'
]
}
];
// Every even index is the token start index, every odd index is the token metadata.
// We get fewer tokens because tokens with the same metadata get collapsed
tokens_now = [
// bbbbbbbbb fffffffff FFF TTT LLLLLLLL
0,
16926743, // 000000010 000001001 001 000 00010111
8,
16793623, // 000000010 000000001 000 000 00010111
9,
16859159, // 000000010 000000101 000 000 00010111
11,
16793623 // 000000010 000000001 000 000 00010111
];
它们以以下方式渲染:
<span class="mtk9 mtki">function</span>
<span class="mtk1"> </span>
<span class="mtk5">f1</span>
<span class="mtk1">() {</span>
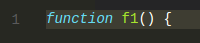
令牌直接从令牌化器以 Uint32Array 形式返回。我们保留了后备 ArrayBuffer,对于上面的例子,在 Chrome 中占用 96 字节。元素本身应该只占用 32 字节(8 个 32 位数字),但我们可能再次观察到一些 v8 元数据开销。
一些数字
为了获得以下测量结果,我选择了三个具有不同特征和不同语法的文件:
| 文件名 | 文件大小 | 行数 | 语言 | 观察 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 22,253 | TypeScript | TypeScript 编译器中使用的实际源文件 |
| bootstrap.min.css | 118.36 KB | 12 | CSS | 精简的 CSS 文件 |
| sqlite3.c | 6.73 MB | 200,904 | C | SQLite 的连接分发文件 |
我在一台性能相当强的 Windows 桌面机器(使用 Electron 32 位)上运行了测试。
我不得不对源代码进行了一些更改,以便进行同类比较,例如确保两个 VS Code 版本使用完全相同的语法,关闭两个版本中的富语言功能,或者取消 VS Code 1.8 中不再存在于 VS Code 1.9 中的 100 堆栈深度限制等。我还不得不将 bootstrap.min.css 分成多行,以使每行少于 20k 字符。
令牌化时间
令牌化在 UI 线程上以让步方式运行,所以我不得不添加一些代码来强制它同步运行,以便测量以下时间(显示 10 次运行的中位数):
| 文件名 | 文件大小 | VS Code 1.8 | VS Code 1.9 | 加速 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 4606.80 毫秒 | 3939.00 毫秒 | 14.50% |
| bootstrap.min.css | 118.36 KB | 776.76 毫秒 | 416.28 毫秒 | 46.41% |
| sqlite3.c | 6.73 MB | 16010.42 毫秒 | 10964.42 毫秒 | 31.52% |
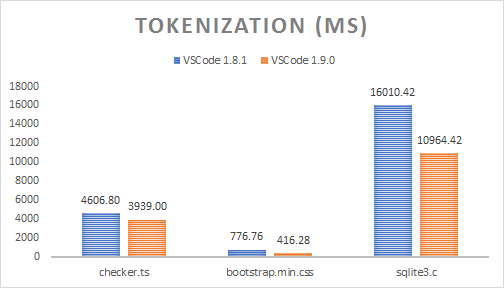
尽管令牌化现在也执行主题匹配,但时间节省可以通过对每一行进行单次遍历来解释。而以前,会有一个令牌化遍历,一个次要遍历以将范围“近似”为字符串,以及第三次遍历以二进制编码令牌,现在令牌直接以二进制编码方式从 TextMate 令牌化引擎生成。需要垃圾回收的生成对象数量也大大减少了。
内存使用
折叠功能会消耗大量内存,特别是对于大文件(这是另一次优化的机会),因此我收集了以下关闭折叠功能后的堆快照数据。这显示了模型占用的内存,不包括原始文件字符串:
| 文件名 | 文件大小 | VS Code 1.8 | VS Code 1.9 | 内存节省 |
|---|---|---|---|---|
| checker.ts | 1.18 MB | 3.37 MB | 2.61 MB | 22.60% |
| bootstrap.min.css | 118.36 KB | 267.00 KB | 201.33 KB | 24.60% |
| sqlite3.c | 6.73 MB | 27.49 MB | 21.22 MB | 22.83% |
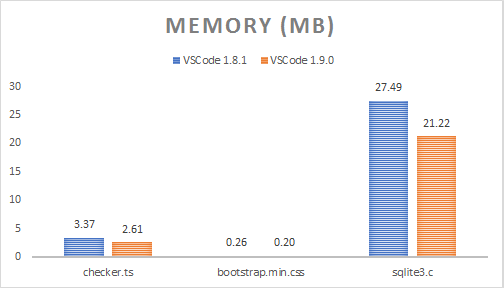
内存使用量的减少可以通过不再保留令牌映射、相同元数据的连续令牌的折叠以及使用 `ArrayBuffer` 作为后备存储来解释。我们可以通过始终将仅包含空白字符的令牌折叠到前一个令牌中来进一步改进,因为空白字符的渲染颜色无关紧要(空白字符是不可见的)。
新的 TextMate 作用域检查器小部件
我们添加了一个新的小部件,以帮助编写和调试主题或语法:您可以在命令面板中运行它,选择 Developer: Inspect Editor Tokens and Scopes(⇧⌘P(Windows, Linux Ctrl+Shift+P))。
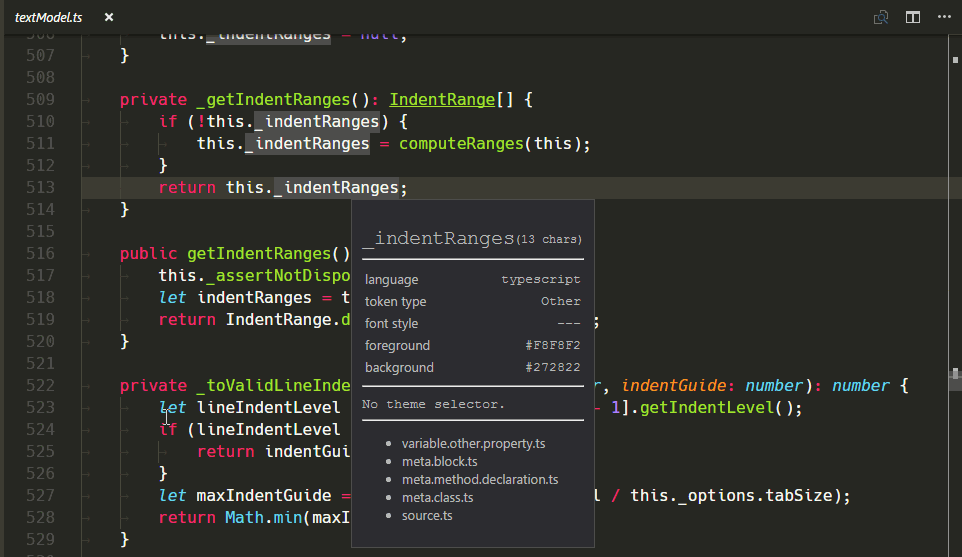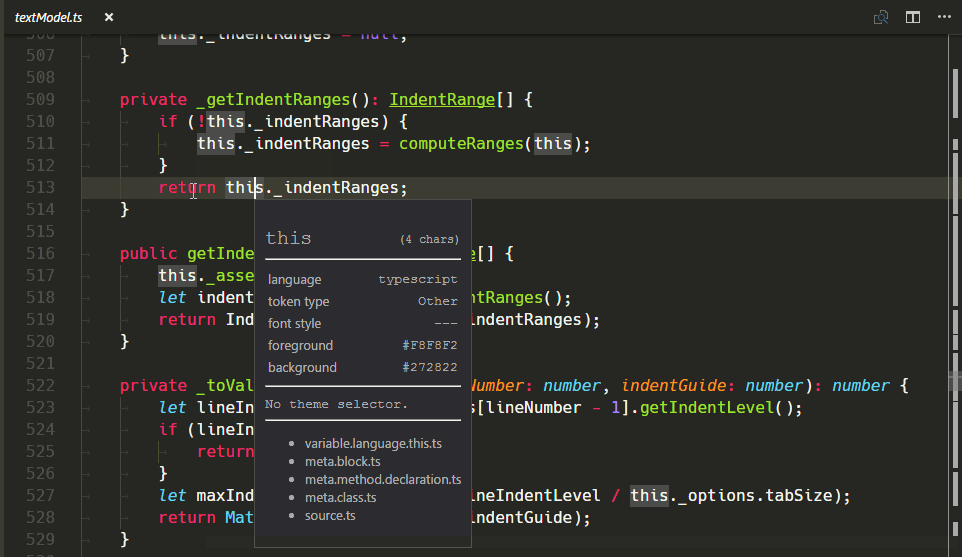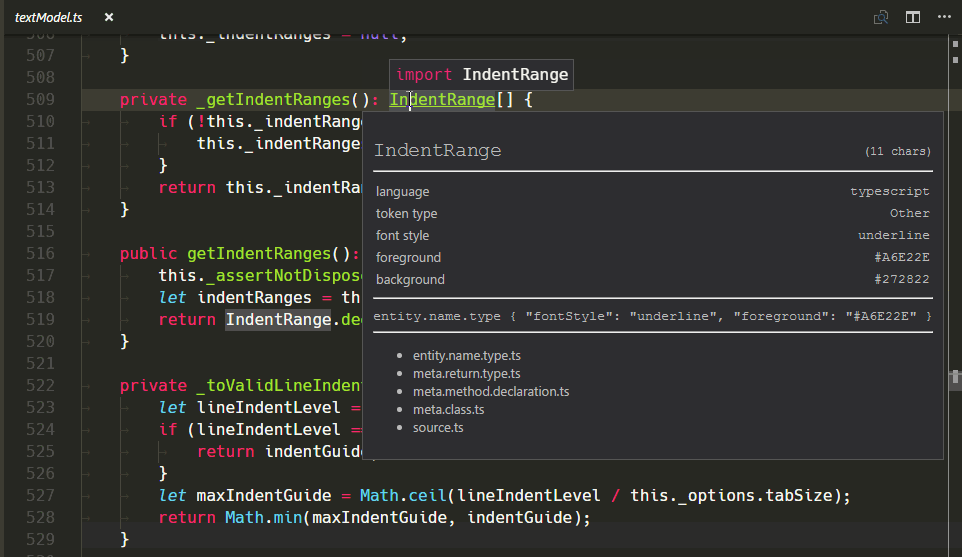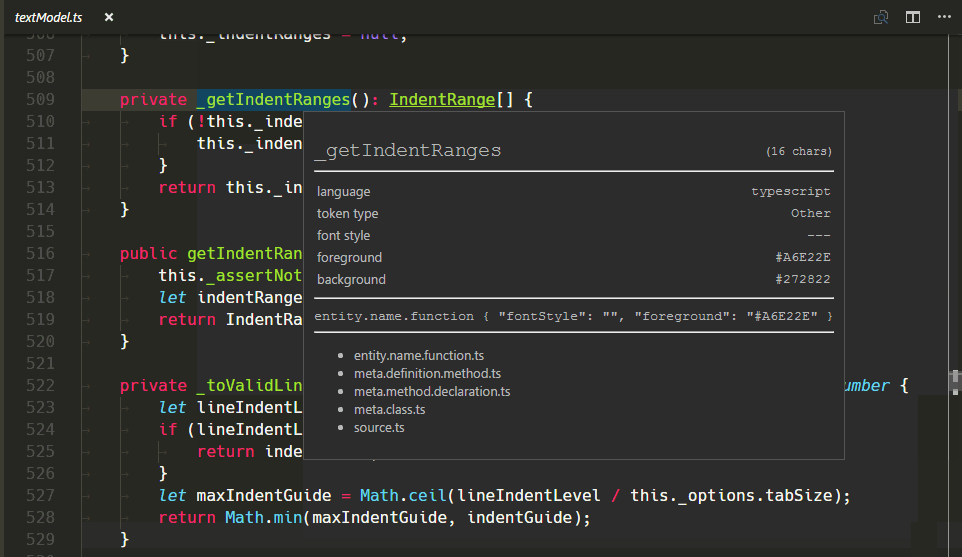
验证变更
对编辑器的此组件进行更改存在一些严重的风险,因为我们方法中的任何错误(在新的 Trie 创建代码中,在新的二进制编码格式中等)都可能导致巨大的用户可见差异。
在 VS Code 中,我们有一个集成测试套件,它会断言我们发布的所有编程语言在五个主题(Light、Light+、Dark、Dark+、High Contrast)中的颜色。这些测试在更改我们的某个主题以及更新某个语法时都非常有用。这 73 个集成测试中的每一个都包含一个固定文件(例如 test.c)以及五个主题的预期颜色(test_c.json),它们在每次提交时都在我们的 CI 构建 上运行。
为了验证令牌化变更,我们使用旧的基于 CSS 的方法,从所有 14 个我们随附的主题(而不仅仅是我们编写的五个主题)的这些测试中收集了颜色化结果。然后,在每次更改之后,我们使用新的基于 Trie 的逻辑运行相同的测试,并使用自定义构建的可视化差异(和补丁)工具,我们会查看每一个颜色差异并找出颜色更改的根本原因。我们使用这种技术至少发现了 2 个错误,并且我们能够更改我们的五个主题,以使 VS Code 版本之间的颜色变化最小化。
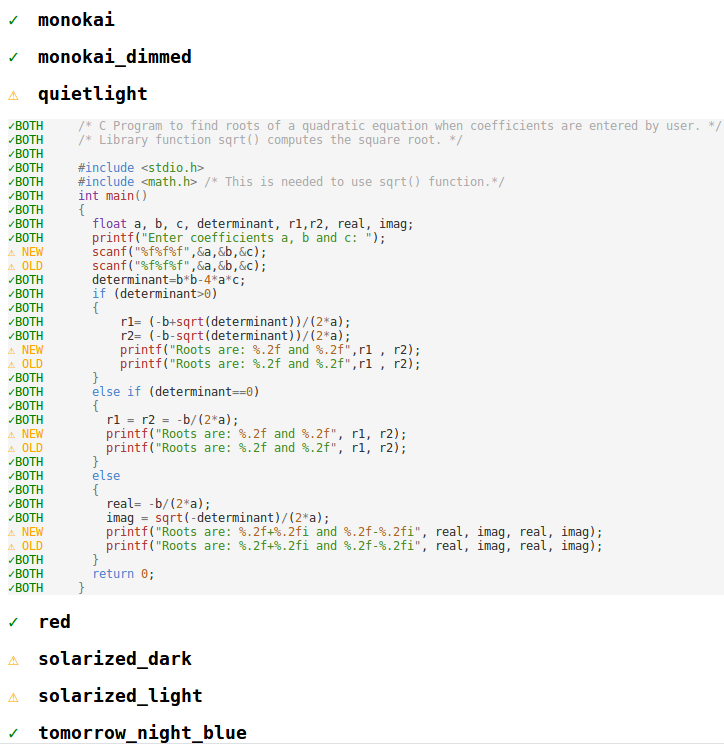
之前和之后
以下是 VS Code 1.8 和现在 VS Code 1.9 中各种颜色主题的显示效果:
Monokai 主题
Quiet Light 主题


Red 主题
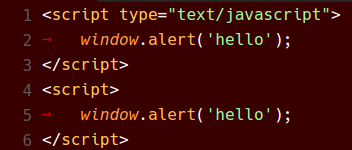
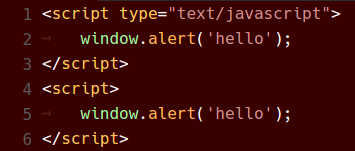
总结
我希望您能感受到升级到 VS Code 1.9 后获得的额外 CPU 时间和 RAM,并且我们能够继续让您以高效愉悦的方式进行编码。
编程愉快!
Alexandru Dima,VS Code 团队成员 @alexdima123