语法高亮指南
语法高亮决定了 Visual Studio Code 编辑器中源代码显示的颜色和样式。它负责将 JavaScript 中的 if 或 for 等关键字与字符串、注释和变量名以不同的颜色区分开。
语法高亮包含两个组成部分:
在深入细节之前,一个好的开始是使用 作用域检查器 工具,探索源代码文件中存在的标记,以及它们匹配的主题规则。要查看语义和语法标记,请在 TypeScript 文件上使用内置主题(例如 Dark+)。
分词
文本分词是将文本分解成片段,并为每个片段分配一个标记类型。
VS Code 的分词引擎由 TextMate 语法 提供支持。TextMate 语法是正则表达式的结构化集合,以 plist (XML) 或 JSON 文件形式编写。VS Code 扩展可以通过 grammars 贡献点来提供语法。
TextMate 分词引擎与渲染器在同一进程中运行,标记会在用户键入时更新。标记不仅用于语法高亮,还用于将源代码分类为注释、字符串、正则表达式等区域。
从 1.43 版本开始,VS Code 还允许扩展通过 语义标记提供程序 提供分词。语义提供程序通常由对源代码文件有更深入理解并能在项目上下文中解析符号的语言服务器实现。例如,一个常量变量名可以在整个项目中以常量高亮显示,而不仅仅是在其声明处。
基于语义标记的高亮被认为是 TextMate 分词高亮的补充。语义高亮建立在语法高亮之上。由于语言服务器加载和分析项目可能需要一些时间,语义标记高亮可能会出现短暂延迟。
本文重点介绍基于 TextMate 的分词。语义分词和主题化将在 语义高亮指南 中进行解释。
TextMate 语法
VS Code 使用 TextMate 语法 作为语法分词引擎。TextMate 语法最初为 TextMate 编辑器发明,由于开源社区创建和维护了大量的语言包,已被许多其他编辑器和 IDE 采用。
TextMate 语法依赖于 Oniguruma 正则表达式,通常以 plist 或 JSON 格式编写。你可以在 这里 找到 TextMate 语法的精彩介绍,并可以查看现有的 TextMate 语法以了解更多它们的工作原理。
TextMate 标记和作用域
标记(Token)是一个或多个属于同一程序元素的字符。示例标记包括 + 和 * 等运算符,myVar 等变量名,或 "my string" 等字符串。
每个标记都关联一个作用域(scope),用于定义标记的上下文。作用域是一个点分隔的标识符列表,用于指定当前标记的上下文。例如,JavaScript 中的 + 操作的作用域是 keyword.operator.arithmetic.js。
主题通过将作用域映射到颜色和样式来实现语法高亮。TextMate 提供了一个 常见作用域列表,许多主题都以这些作用域为目标。为了让你的语法尽可能广泛地获得支持,请尝试基于现有作用域进行构建,而不是定义新的作用域。
作用域是嵌套的,因此每个标记也与一个父作用域列表相关联。下面的示例使用 作用域检查器 来显示一个简单的 JavaScript 函数中 + 运算符的作用域层次结构。最具体的作用域列在顶部,然后是更通用的父作用域。
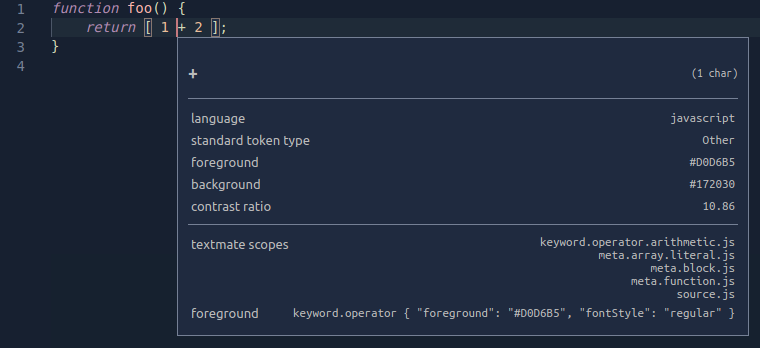
父作用域信息也用于主题化。当主题定位某个作用域时,所有具有该父作用域的标记都将被着色,除非主题为其单个作用域提供了更具体着色。
贡献基本语法
VS Code 支持 JSON 格式的 TextMate 语法。这些语法通过 grammars 贡献点 进行贡献。
每个语法贡献都指定:语法适用的语言标识符、语法标记的顶层作用域名称,以及语法文件的相对路径。下面的示例显示了为虚构的 abc 语言所做的语法贡献。
{
"contributes": {
"languages": [
{
"id": "abc",
"extensions": [".abc"]
}
],
"grammars": [
{
"language": "abc",
"scopeName": "source.abc",
"path": "./syntaxes/abc.tmGrammar.json"
}
]
}
}
语法文件本身由一个顶层规则组成。这通常分为一个 patterns 部分,列出程序的顶层元素,以及一个 repository,定义每个元素。语法中的其他规则可以通过 { "include": "#id" } 来引用 repository 中的元素。
示例 abc 语法将字母 a、b 和 c 标记为关键字,并将括号嵌套标记为表达式。
{
"scopeName": "source.abc",
"patterns": [{ "include": "#expression" }],
"repository": {
"expression": {
"patterns": [{ "include": "#letter" }, { "include": "#paren-expression" }]
},
"letter": {
"match": "a|b|c",
"name": "keyword.letter"
},
"paren-expression": {
"begin": "\\(",
"end": "\\)",
"beginCaptures": {
"0": { "name": "punctuation.paren.open" }
},
"endCaptures": {
"0": { "name": "punctuation.paren.close" }
},
"name": "expression.group",
"patterns": [{ "include": "#expression" }]
}
}
}
语法引擎将尝试依次将 expression 规则应用于文档中的所有文本。对于一个简单的程序,例如:
a
(
b
)
x
(
(
c
xyz
)
)
(
a
示例语法生成以下作用域(从左到右,从最具体到最不具体的作用域):
a keyword.letter, source.abc
( punctuation.paren.open, expression.group, source.abc
b keyword.letter, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
x source.abc
( punctuation.paren.open, expression.group, source.abc
( punctuation.paren.open, expression.group, expression.group, source.abc
c keyword.letter, expression.group, expression.group, source.abc
xyz expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
( punctuation.paren.open, expression.group, source.abc
a keyword.letter, expression.group, source.abc
请注意,未被任何规则匹配的文本(如字符串 xyz)会被包含在当前作用域中。文件末尾的最后一个右括号是 expression.group 的一部分,即使 end 规则未被匹配,因为在 end 规则被匹配之前找到了 end-of-document。
嵌入语言
如果你的语法包含父语言中的嵌入语言,例如 HTML 中的 CSS 样式块,你可以使用 embeddedLanguages 贡献点来告诉 VS Code 将嵌入语言视为独立于父语言。这确保了括号匹配、注释和其他基本语言功能在嵌入语言中按预期工作。
embeddedLanguages 贡献点将嵌入语言中的作用域映射到一个顶层语言作用域。在下面的示例中,meta.embedded.block.javascript 作用域中的任何标记都将被视为 JavaScript 内容。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/abc.tmLanguage.json",
"scopeName": "source.abc",
"embeddedLanguages": {
"meta.embedded.block.javascript": "javascript"
}
}
]
}
}
现在,如果你尝试在标记为 meta.embedded.block.javascript 的标记集合中注释代码或触发代码片段,它们将获得正确的 // JavaScript 风格注释和正确的 JavaScript 代码片段。
开发新的语法扩展
要快速创建新的语法扩展,请使用 VS Code 的 Yeoman 模板 运行 yo code 并选择 New Language 选项。
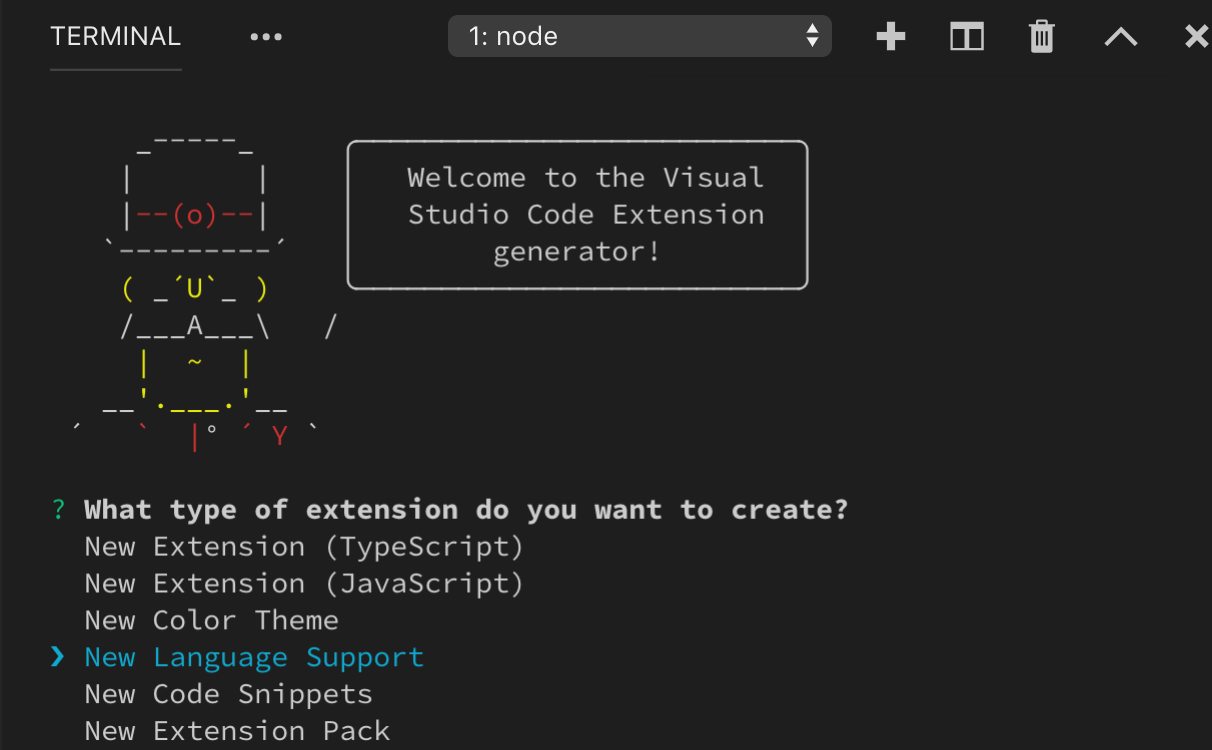
Yeoman 将引导你完成一些基本问题来构建新扩展。创建新语法时需要回答的重要问题是:
Language id- 你的语言的唯一标识符。Language name- 你的语言的可读名称。Scope names- 你语法的根 TextMate 作用域名称。
生成器假设你想为新语言定义一种新语法。如果你正在为现有语言创建语法,只需用目标语言的信息填写这些内容,并确保删除生成的 package.json 中的 languages 贡献点。
回答完所有问题后,Yeoman 将创建一个具有以下结构的新扩展:
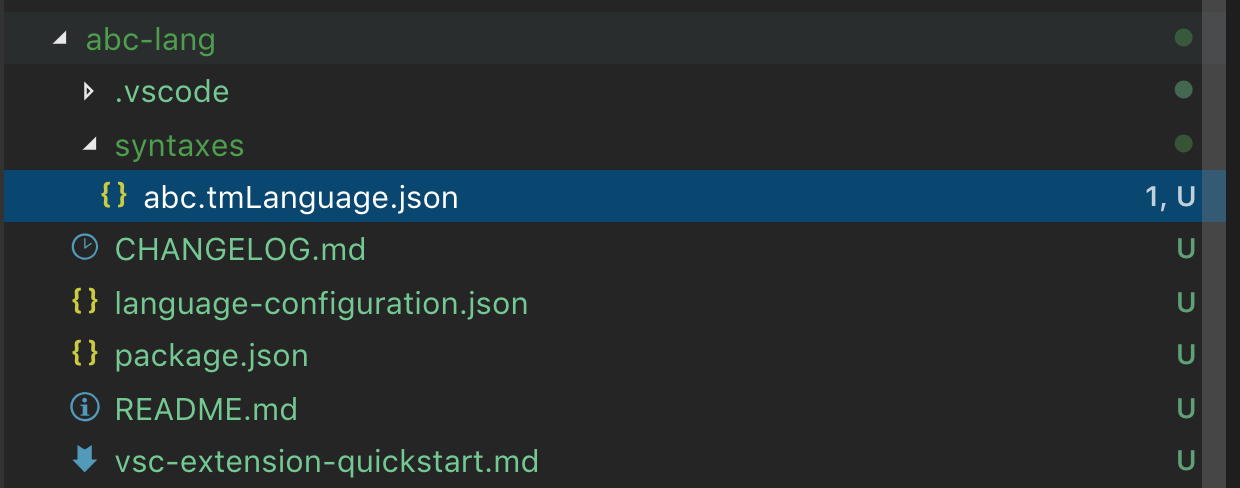
请记住,如果你为 VS Code 已知的语言贡献语法,请务必删除生成的 package.json 中的 languages 贡献点。
转换现有 TextMate 语法
yo code 也可以帮助将现有的 TextMate 语法转换为 VS Code 扩展。同样,首先运行 yo code 并选择 Language extension。当被问及现有的语法文件时,提供 .tmLanguage 或 .json TextMate 语法文件的完整路径。
使用 YAML 编写语法
随着语法变得越来越复杂,以 JSON 格式理解和维护它可能会变得困难。如果你发现自己编写复杂的正则表达式或需要添加注释来解释语法的各个方面,请考虑改用 YAML 来定义你的语法。
YAML 语法与基于 JSON 的语法结构完全相同,但允许你使用 YAML 更简洁的语法,以及多行字符串和注释等功能。
VS Code 只能加载 JSON 语法,因此基于 YAML 的语法必须转换为 JSON。 js-yaml 包 和命令行工具可以轻松完成此操作。
# Install js-yaml as a development only dependency in your extension
$ npm install js-yaml --save-dev
# Use the command-line tool to convert the yaml grammar to json
$ npx js-yaml syntaxes/abc.tmLanguage.yaml > syntaxes/abc.tmLanguage.json
注入语法
注入语法允许你扩展现有语法。注入语法是一种常规的 TextMate 语法,它被注入到现有语法中的特定作用域。注入语法的应用示例:
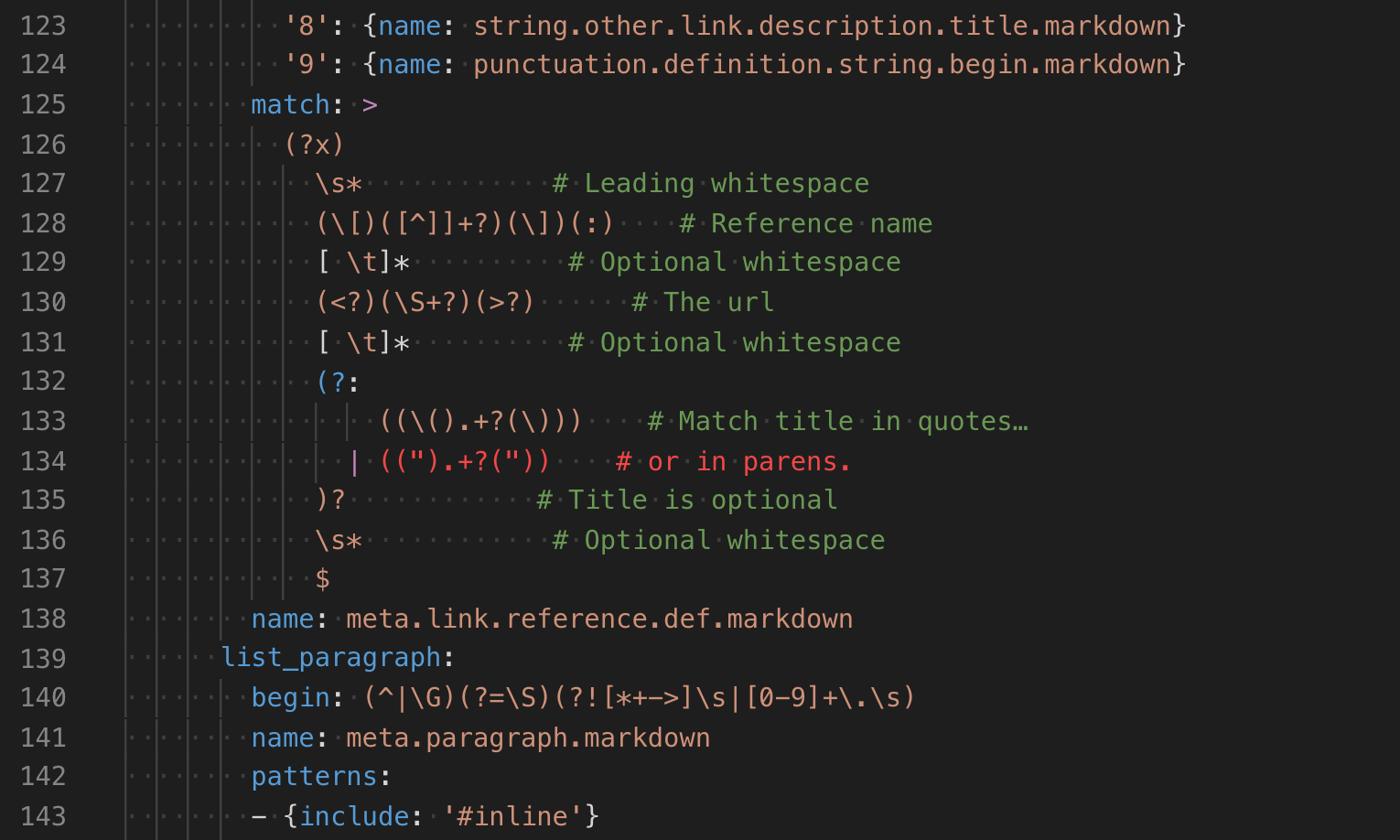
- 高亮注释中的
TODO等关键字。 - 为现有语法添加更具体的作用域信息。
- 为 Markdown 围栏代码块添加新语言的高亮。
创建基本注入语法
注入语法通过 package.json 贡献,就像常规语法一样。但是,注入语法不指定 language,而是使用 injectTo 来指定要注入语法的目标语言作用域列表。
在本例中,我们将创建一个简单的注入语法,用于高亮 JavaScript 注释中的 TODO 关键字。要在 JavaScript 文件中应用我们的注入语法,我们在 injectTo 中使用 source.js 目标语言作用域。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "todo-comment.injection",
"injectTo": ["source.js"]
}
]
}
}
语法本身是标准的 TextMate 语法,但具有顶层的 injectionSelector 条目。injectionSelector 是一个作用域选择器,用于指定应将注入语法应用于哪些作用域。在我们的示例中,我们希望高亮所有 // 注释中的 TODO。使用 作用域检查器,我们发现 JavaScript 的双斜杠注释的作用域是 comment.line.double-slash,所以我们的注入选择器是 L:comment.line.double-slash。
{
"scopeName": "todo-comment.injection",
"injectionSelector": "L:comment.line.double-slash",
"patterns": [
{
"include": "#todo-keyword"
}
],
"repository": {
"todo-keyword": {
"match": "TODO",
"name": "keyword.todo"
}
}
}
注入选择器中的 L: 表示注入添加到现有语法规则的左侧。这基本上意味着我们的注入语法的规则将在任何现有语法规则之前应用。
嵌入语言
注入语法也可以为其父语法贡献嵌入语言。与普通语法一样,注入语法可以使用 embeddedLanguages 将嵌入语言的作用域映射到一个顶层语言作用域。
例如,一个突出显示 JavaScript 字符串中 SQL 查询的扩展可以使用 embeddedLanguages 来确保标记为 meta.embedded.inline.sql 的字符串中的所有标记都被视为 SQL,以实现括号匹配和代码片段选择等基本语言功能。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"meta.embedded.inline.sql": "sql"
}
}
]
}
}
标记类型和嵌入语言
注入语言和嵌入语言有一个额外的复杂性:默认情况下,VS Code 将字符串内的所有标记视为字符串内容,并将注释中的所有标记视为标记内容。由于括号匹配和自动闭合对等功能在字符串和注释内部被禁用,如果嵌入语言出现在字符串或注释内部,这些功能在嵌入语言中也将被禁用。
要覆盖此行为,你可以使用 meta.embedded.* 作用域来重置 VS Code 对标记为字符串或注释内容的标记。最好始终将嵌入语言包装在 meta.embedded.* 作用域中,以确保 VS Code 正确处理嵌入语言。
如果你无法在语法中添加 meta.embedded.* 作用域,你也可以在语法的贡献点中使用 tokenTypes 将特定作用域映射到内容模式。下面的 tokenTypes 部分确保 my.sql.template.string 作用域中的任何内容都被视为源代码。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"my.sql.template.string": "sql"
},
"tokenTypes": {
"my.sql.template.string": "other"
}
}
]
}
}
主题
主题化是关于为标记分配颜色和样式。主题化规则在颜色主题中指定,但用户可以在用户设置中自定义主题化规则。
TextMate 主题规则在 tokenColors 中定义,其语法与常规 TextMate 主题相同。每条规则定义一个 TextMate 作用域选择器以及结果的颜色和样式。
在评估标记的颜色和样式时,当前标记的作用域会与规则的选择器进行匹配,以找到每个样式属性(前景、粗体、斜体、下划线)的最具体规则。
颜色主题指南 描述了如何创建颜色主题。语义标记的主题化将在 语义高亮指南 中进行解释。
作用域检查器
VS Code 内置的作用域检查器工具有助于调试语法和语义标记。它显示文件当前位置的标记和语义标记的作用域,以及有关哪些主题规则应用于该标记的元数据。
可以通过命令面板中的 Developer: Inspect Editor Tokens and Scopes 命令触发作用域检查器,或为其 创建快捷键。
{
"key": "cmd+alt+shift+i",
"command": "editor.action.inspectTMScopes"
}
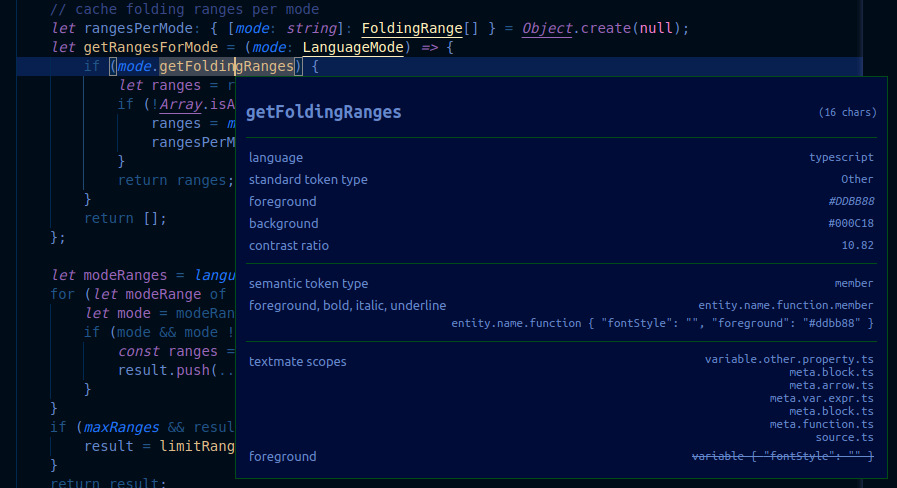
作用域检查器显示以下信息:
- 当前标记。
- 关于标记的元数据以及其计算外观的信息。如果你正在处理嵌入语言,这里重要的条目是
language和token type。 - 当当前语言存在语义标记提供程序并且当前主题支持语义高亮时,将显示语义标记部分。它显示当前的语义标记类型和修饰符,以及匹配语义标记类型和修饰符的主题规则。
- TextMate 部分显示当前 TextMate 标记的作用域列表,最具体的作用域在顶部。它还显示匹配作用域的最具体主题规则。这仅显示负责标记当前样式的规则,而不显示覆盖的规则。如果存在语义标记,则仅在与语义标记匹配的规则不同的情况下显示主题规则。