文本缓冲区重新实现
2018年3月23日,吕鹏,@njukidreborn
Visual Studio Code 1.21 版本包含一个全新的文本缓冲区实现,它在速度和内存使用方面都更具性能。在这篇博客文章中,我想讲述我们如何选择和设计导致这些改进的数据结构和算法的故事。
关于 JavaScript 程序的性能讨论通常涉及一个关于应该在原生代码中实现多少内容的讨论。对于 VS Code 文本缓冲区,这些讨论开始于一年多以前。在一次深入的探索中,我们发现 C++ 实现的文本缓冲区可以显著节省内存,但我们没有看到我们所期望的性能提升。在自定义原生表示和 V8 字符串之间转换字符串的成本很高,在我们的案例中,它损害了通过在 C++ 中实现文本缓冲区操作所获得的任何性能。我们将在本文末尾更详细地讨论这一点。
由于不采用原生方式,我们不得不寻找改进我们的 JavaScript/TypeScript 代码的方法。诸如 Vyacheslav Egorov 的这篇博客文章之类的帖子展示了如何将 JavaScript 引擎推向极限并尽可能地榨取性能。即使没有低级引擎技巧,通过使用更合适的数据结构和更快的算法,仍然可以将速度提高一个或多个数量级。
以前的文本缓冲区数据结构
编辑器的心智模型是基于行的。开发人员逐行阅读和编写源代码,编译器提供基于行/列的诊断,堆栈跟踪包含行号,分词引擎逐行运行,等等。尽管简单,但为 VS Code 提供支持的文本缓冲区实现自 Monaco 项目启动之日起就没有太大变化。我们使用一个行数组,它运行得非常好,因为典型的文本文档相对较小。当用户输入时,我们在数组中找到要修改的行并替换它。当插入新行时,我们将一个新的行对象拼接进行数组中,JavaScript 引擎会为我们完成繁重的工作。
然而,我们不断收到报告称,打开某些文件会导致 VS Code 中出现内存不足崩溃。例如,一位用户未能打开一个 35 MB 的文件。根本原因是该文件行数过多,达到 1370 万行。我们为每一行创建一个 ModelLine 对象,每个对象大约使用 40-60 字节,因此行数组使用了大约 600MB 的内存来存储文档。这大约是初始文件大小的 20 倍!
行数组表示的另一个问题是文件打开速度。为了构建行数组,我们必须按换行符分割内容,这样每行都会得到一个字符串对象。分割本身会损害性能,您将在下面的基准测试中看到。
寻找新的文本缓冲区实现
旧的行数组表示创建耗时且占用大量内存,但它提供了快速的行查找。在一个完美的世界中,我们将只存储文件的文本,而不存储任何额外的元数据。因此,我们开始寻找需要较少元数据的数据结构。在审查了各种数据结构之后,我发现 piece table 可能是个不错的起点。
通过使用分块表避免过多的元数据
分块表是一种用于表示文本文档(TypeScript 中的源代码)一系列编辑的数据结构。
class PieceTable {
original: string; // original contents
added: string; // user added contents
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
}
enum NodeType {
Original,
Added
}
文件最初加载后,分块表在 original 字段中包含整个文件内容。added 字段为空。有一个类型为 NodeType.Original 的单个节点。当用户在文件末尾输入时,我们将新内容附加到 added 字段,并在节点列表末尾插入一个类型为 NodeType.Added 的新节点。同样,当用户在节点中间进行编辑时,我们将根据需要拆分该节点并插入一个新节点。
下面的动画展示了如何在分块表结构中逐行访问文档。它有两个缓冲区(original 和 added)和三个节点(这是由于在 original 内容中间插入造成的)。
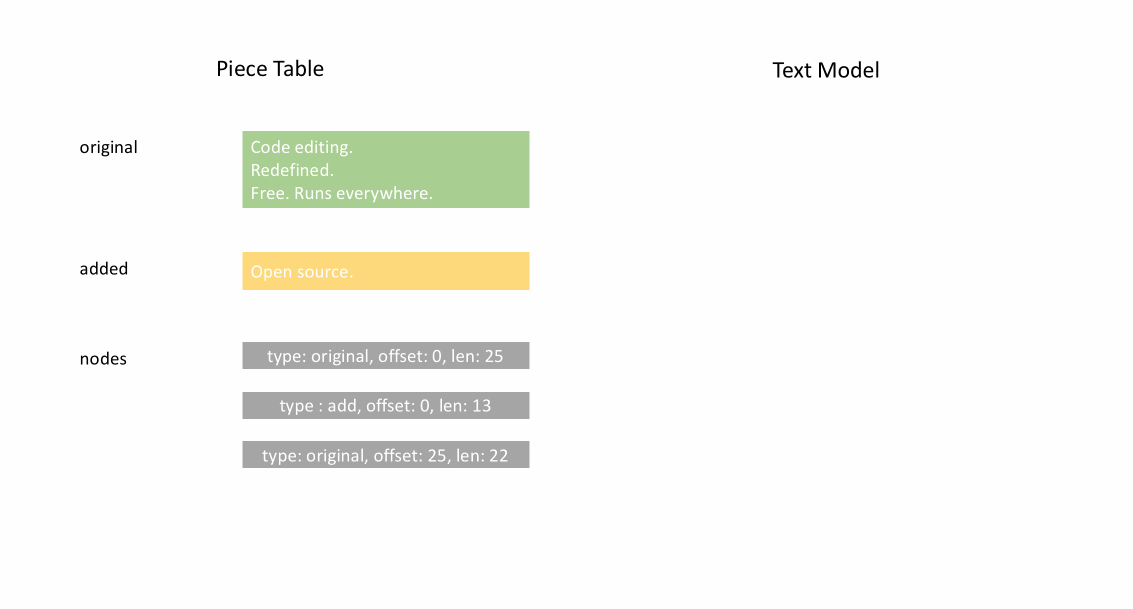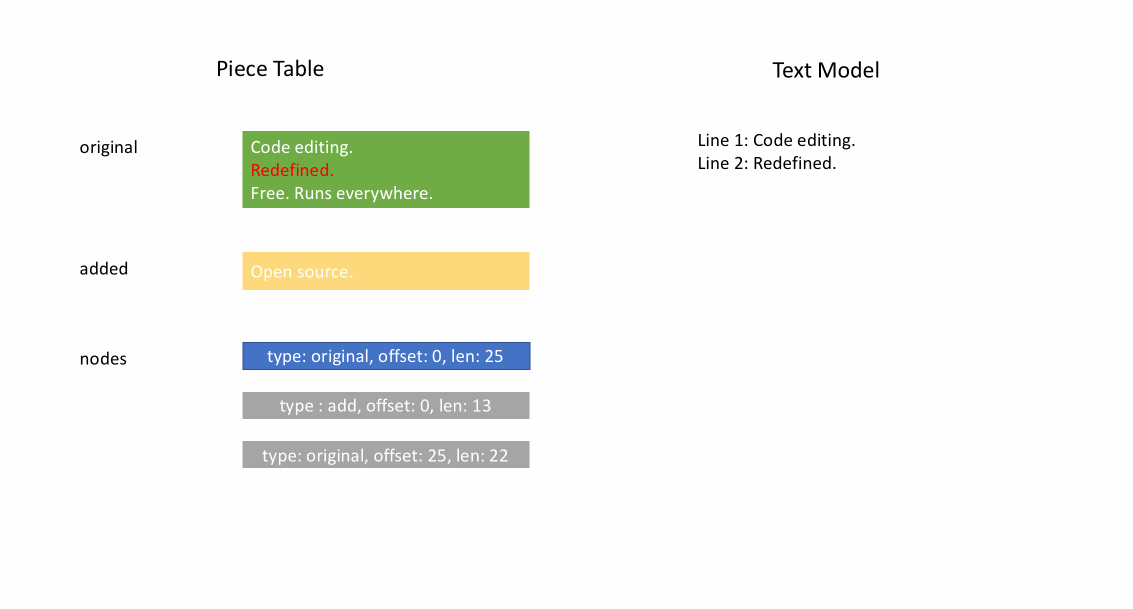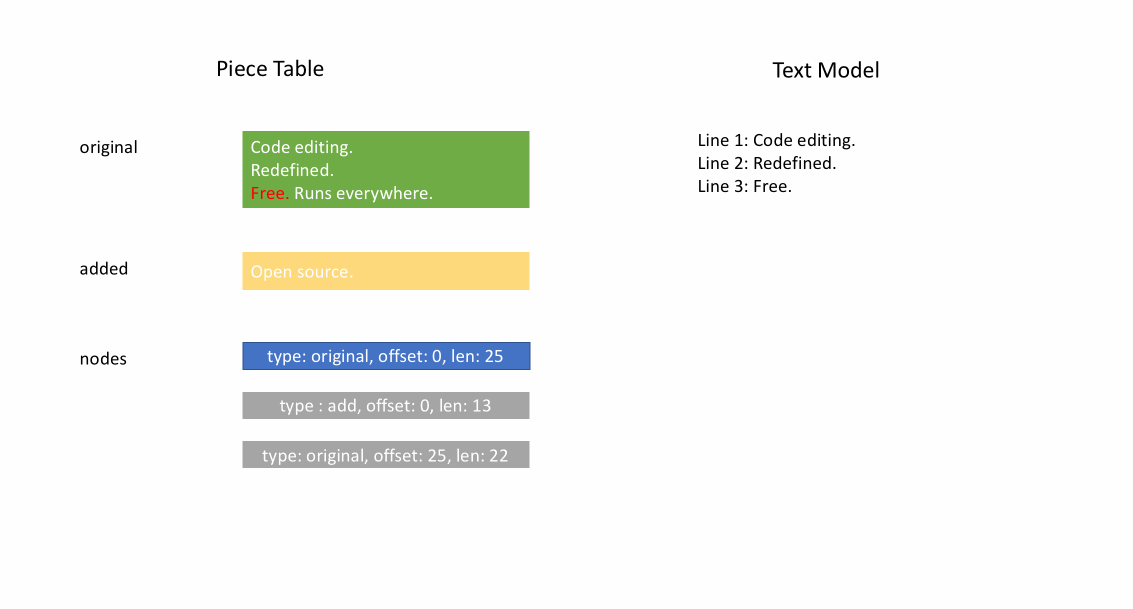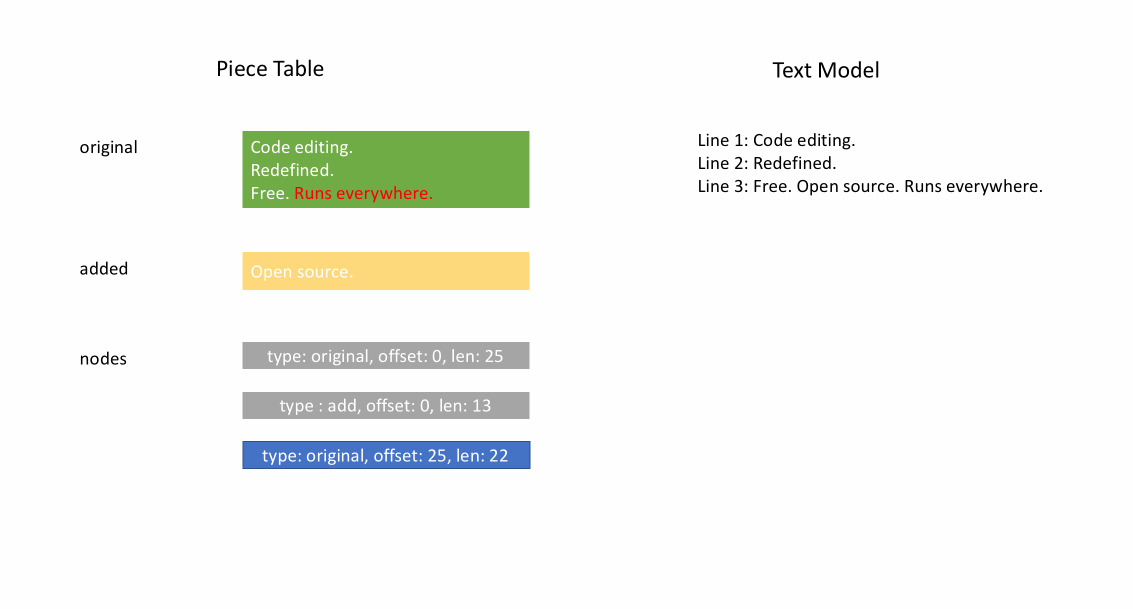
分块表的初始内存使用量接近文档大小,修改所需的内存与编辑次数和添加的文本成比例。因此,通常分块表能很好地利用内存。然而,低内存使用的代价是访问逻辑行速度较慢。例如,如果您想获取第 1000 行的内容,唯一的方法是从文档开头遍历每个字符,找到前 999 个换行符,然后读取每个字符直到下一个换行符。
使用缓存加快行查找
传统的分块表节点只包含偏移量,但我们可以添加换行符信息以加快行内容查找。存储换行符位置的直观方法是存储节点文本中遇到的每个换行符的偏移量。
class PieceTable {
original: string;
added: string;
nodes: Node[];
}
class Node {
type: NodeType;
start: number;
length: number;
lineStarts: number[];
}
enum NodeType {
Original,
Added
}
例如,如果您想访问给定 Node 实例中的第二行,您可以读取 node.lineStarts[0] 和 node.lineStarts[1],这将给出行的开始和结束的相对偏移量。由于我们知道一个节点有多少个换行符,因此访问文档中的随机行是直截了当的:从第一个节点开始读取每个节点,直到找到目标换行符。
该算法仍然很简单,而且比以前更好用,因为我们现在可以跳过整个文本块,而不是逐个字符迭代。我们稍后会看到我们甚至可以做得更好。
避免字符串连接陷阱
分块表包含两个缓冲区,一个用于从磁盘加载的原始内容,另一个用于用户编辑。在 VS Code 中,我们使用 Node.js 的 fs.readFile 加载文本文件,该函数以 64KB 的块提供内容。因此,当文件很大时,例如 64 MB,我们将收到 1000 个块。收到所有块后,我们可以将它们连接成一个大字符串,并将其存储在分块表的 original 字段中。
这听起来很合理,直到 V8 踩到你的痛点。我尝试打开一个 500MB 的文件,并得到了一个异常,因为在我使用的 V8 版本中,最大字符串长度是 256MB。这个限制将在 V8 的未来版本中提高到 1GB,但这并不能真正解决问题。
我们不是持有 original 和 added 缓冲区,而是可以持有一个缓冲区列表。我们可以尝试保持该列表简短,或者我们可以借鉴 fs.readFile 返回的内容,并避免任何字符串连接。每次我们从磁盘接收到 64KB 的块时,我们都会将其直接推送到 buffers 数组并创建一个指向此缓冲区的节点。
class PieceTable {
buffers: string[];
nodes: Node[];
}
class Node {
bufferIndex: number;
start: number; // start offset in buffers[bufferIndex]
length: number;
lineStarts: number[];
}
通过使用平衡二叉树加速行查找
解决了字符串连接问题后,我们现在可以打开大文件,但这又引出了另一个潜在的性能问题。假设我们加载一个 64MB 的文件,分块表将有 1000 个节点。即使我们缓存了每个节点中的换行符位置,我们也不知道哪个绝对行号在哪一个节点中。要获取一行内容,我们必须遍历所有节点,直到找到包含该行的节点。在我们的示例中,根据我们查找的行号,我们必须迭代多达 1000 个节点。因此,最坏情况下的时间复杂度是 O(N)(N 是节点数)。
在每个节点中缓存绝对行号并对节点列表进行二分查找可以提高查找速度,但是每当我们修改一个节点时,我们必须访问所有后续节点以应用行号增量。这是不可行的,但是二分查找的想法很好。为了达到相同的效果,我们可以利用平衡二叉树。
现在我们必须决定使用什么元数据作为键来比较树节点。如前所述,使用节点在文档中的偏移量或绝对行号将使编辑操作的时间复杂度达到 O(N)。如果我们想要 O(log n) 的时间复杂度,我们需要一些只与树节点的子树相关的东西。因此,当用户编辑文本时,我们重新计算修改节点的元数据,然后将元数据更改沿父节点一直冒泡到根节点。
如果一个 Node 只有四个属性(bufferIndex, start, length, lineStarts),那么找到结果需要几秒钟。为了更快,我们还可以存储节点左子树的文本长度和换行符计数。这样,从树的根节点按偏移量或行号搜索就可以高效。存储右子树的元数据也是一样的,但我们不需要同时缓存两者。
这些类现在看起来像这样
class PieceTable {
buffers: string[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: number;
length: number;
lineStarts: number[];
left_subtree_length: number;
left_subtree_lfcnt: number;
left: Node;
right: Node;
parent: Node;
}
在所有不同类型的平衡二叉树中,我们选择红黑树,因为它更“编辑”友好。
减少对象分配
假设我们存储每个节点中的换行符偏移量。每当我们更改节点时,我们可能必须更新换行符偏移量。例如,假设我们有一个包含 999 个换行符的节点,lineStarts 数组有 1000 个元素。如果我们平均分割节点,那么我们将创建两个节点,每个节点都有一个包含大约 500 个元素的数组。由于我们不直接在线性内存空间上操作,将数组分割成两个比仅仅移动指针的成本更高。
好消息是分块表中的缓冲区要么是只读的(原始缓冲区),要么是追加的(已更改的缓冲区),因此缓冲区内的换行符不会移动。Node 可以简单地持有对其相应缓冲区上的换行符偏移量的两个引用。我们做得越少,性能就越好。我们的基准测试表明,应用此更改使我们实现中的文本缓冲区操作速度提高了三倍。但关于实际实现将在稍后讨论。
class Buffer {
value: string;
lineStarts: number[];
}
class BufferPosition {
index: number; // index in Buffer.lineStarts
remainder: number;
}
class PieceTable {
buffers: Buffer[];
rootNode: Node;
}
class Node {
bufferIndex: number;
start: BufferPosition;
end: BufferPosition;
...
}
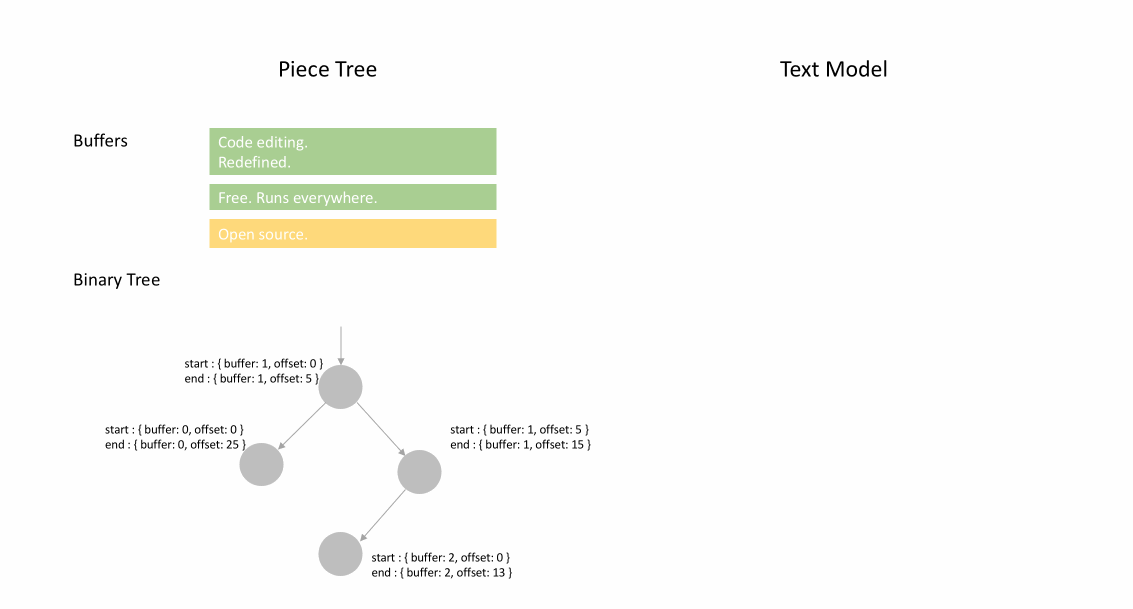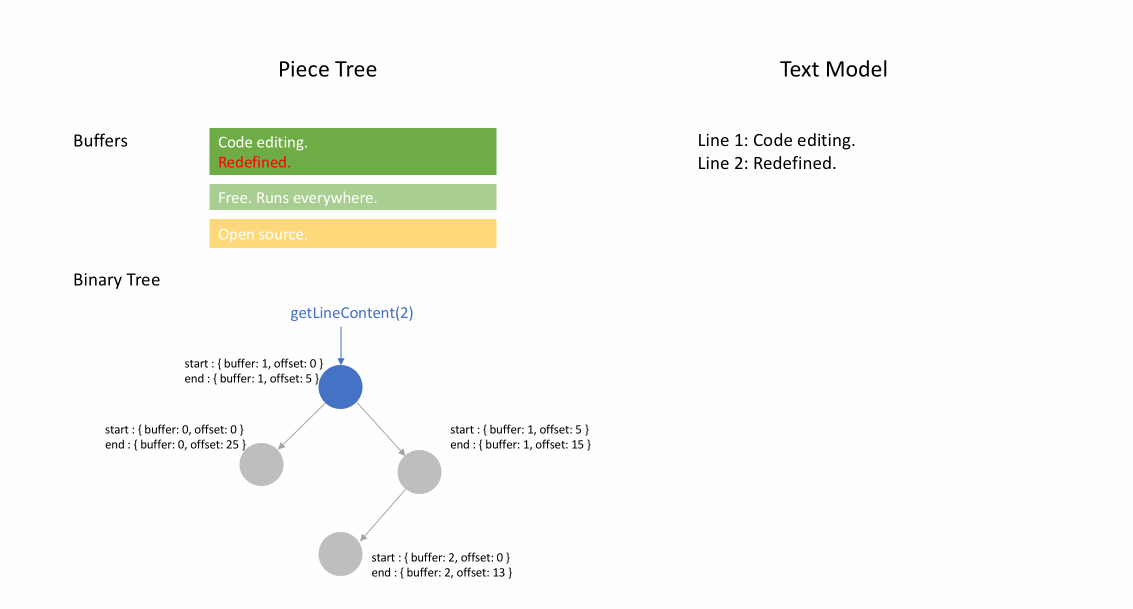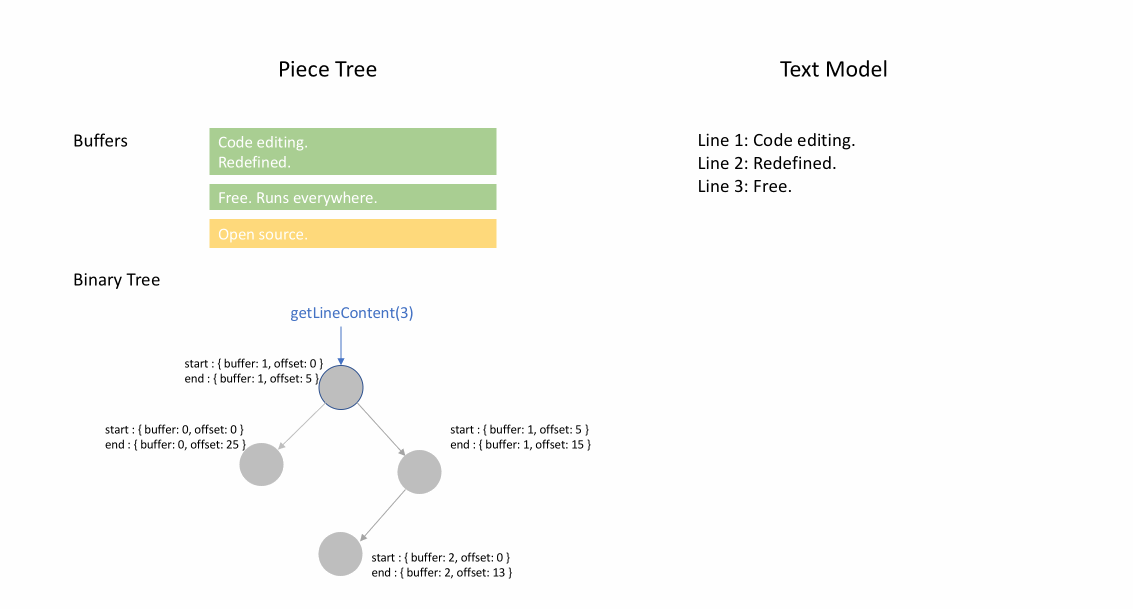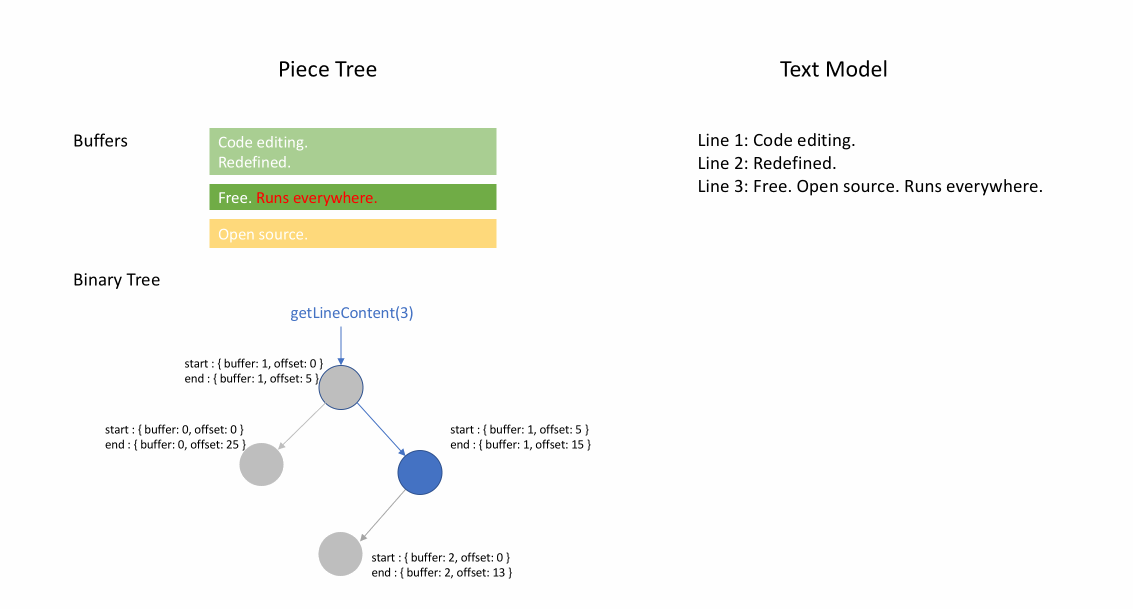
分块树
我很想把这个文本缓冲区称为“带有红黑树的多缓冲区分块表,为行模型优化”。但在我们每天的站立会议中,每个人分享他们所做的事情都被限制在 90 秒内,重复这个长名字多次是不明智的。所以我简单地称它为“分块树”,它反映了它的本质。
对这种数据结构有理论上的理解是一回事,实际性能又是另一回事。您使用的语言、代码运行的环境、客户端调用您的 API 的方式以及其他因素可能会显著影响结果。基准测试可以提供全面的图片,因此我们针对原始行数组实现和分块树实现对小型/中型/大型文件进行了基准测试。
准备工作
为了提供有说服力的结果,我在网上找了一些实际的文件:
- checker.ts - 1.46 MB,2.6 万行。
- sqlite.c - 4.31MB,12.8 万行。
- 俄英双语词典 - 14MB,55.2 万行。
并手动创建了几个大文件:
- 新打开的 VS Code Insider 的 Chromium 堆快照 - 54MB,300 万行。
- checker.ts X 128 - 184MB,300 万行。
1. 内存使用
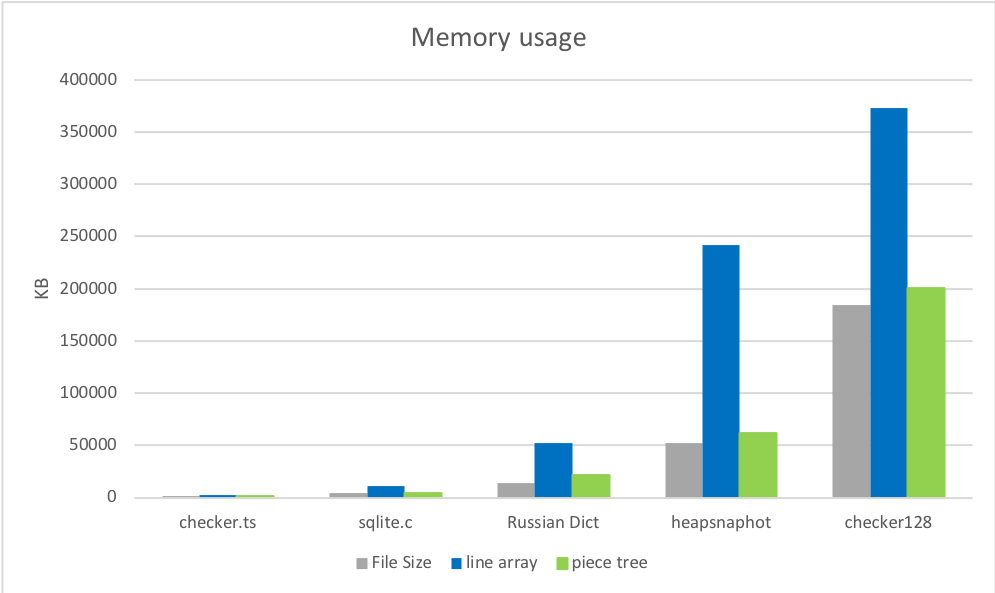
分块树加载后的内存使用量非常接近原始文件大小,并且明显低于旧实现。第一轮,分块树胜出。
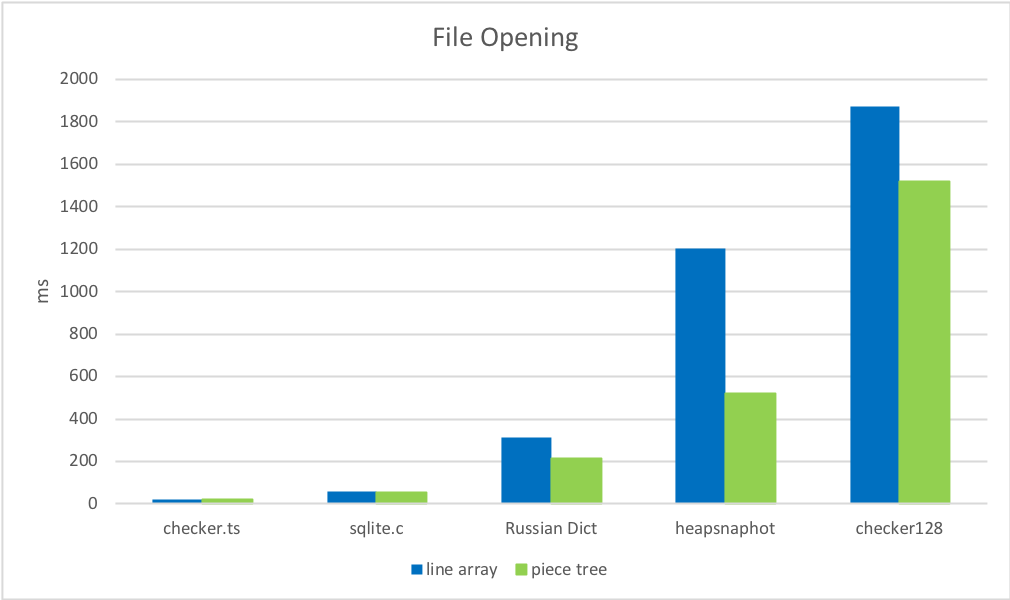
2. 文件打开时间
查找和缓存换行符比将文件分割成字符串数组快得多。
3. 编辑
我模拟了两种工作流程:
- 在文档中的随机位置进行编辑。
- 按顺序输入。
我尝试模拟这两种场景:对文档进行 1000 次随机编辑或 1000 次顺序插入,然后查看每个文本缓冲区需要多少时间。
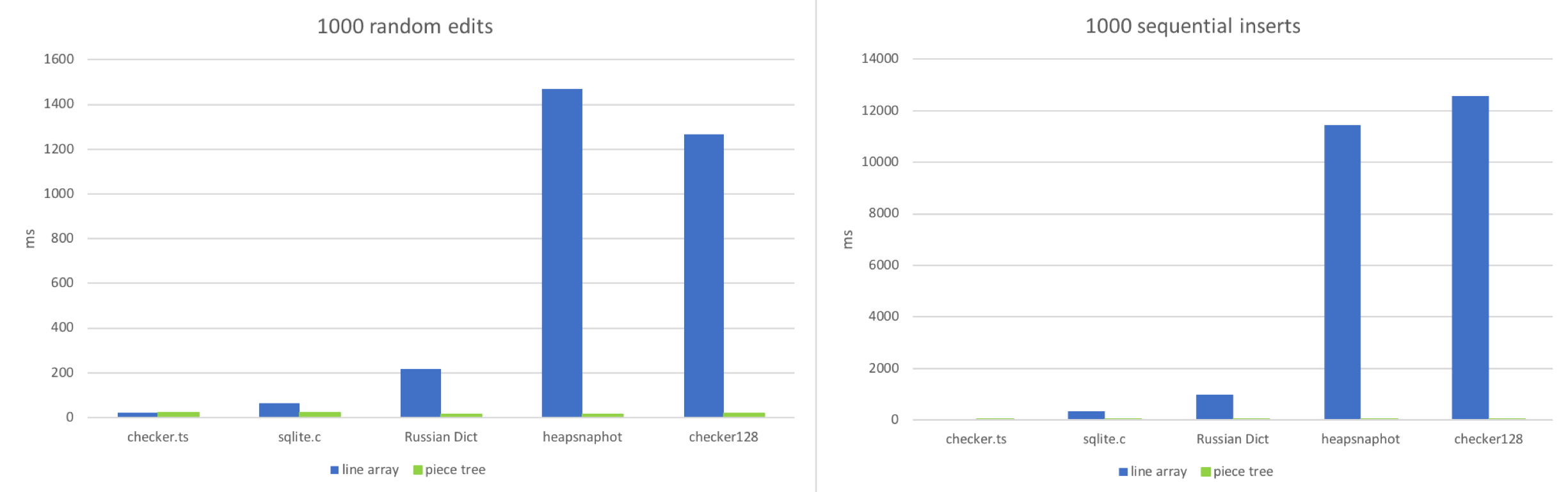
正如预期的那样,当文件非常小时,行数组表现出色。访问小数组中的随机位置并调整大约 100~150 个字符的字符串非常快。当文件有大量行(10 万+)时,行数组开始出现问题。大文件中的顺序插入使这种情况变得更糟,因为 JavaScript 引擎为了调整大数组的大小做了大量工作。分块树表现稳定,因为每次编辑都只是一个字符串追加和几个红黑树操作。
4. 阅读
对于我们的文本缓冲区,最常用的方法是 getLineContent。它被视图代码、分词器、链接检测器以及几乎所有依赖文档内容的组件调用。一些代码遍历整个文件,例如链接检测器,而另一些代码只读取连续行的窗口,例如视图代码。因此,我着手在各种场景下对这个方法进行基准测试:
- 在进行 1000 次随机编辑后,调用所有行的
getLineContent。 - 在进行 1000 次顺序插入后,调用所有行的
getLineContent。 - 在进行 1000 次随机编辑后,读取 10 个不同的行窗口。
- 在进行 1000 次顺序插入后,读取 10 个不同的行窗口。
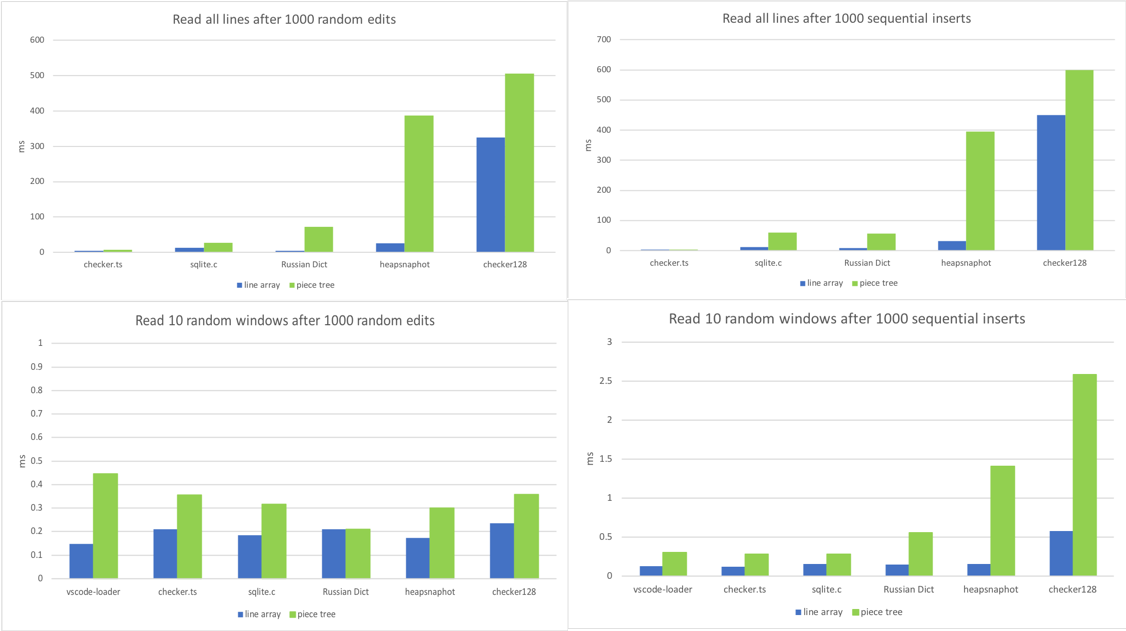
瞧,我们找到了分块树的阿喀琉斯之踵。一个包含数千次编辑的大文件,将导致数千或数万个节点。即使查找一行是 O(log N),其中 N 是节点数,这仍然比行数组所拥有的 O(1) 要慢得多。
数千次编辑相对罕见。您可能在大型文件中替换了经常出现的字符序列后达到这个数量。此外,我们谈论的是每次 getLineContent 调用仅需微秒,因此目前我们并不担心。大多数 getLineContent 调用都来自视图渲染和标记化,而行内容的后处理更耗时。DOM 构建和渲染或视图端口的标记化通常需要数十毫秒,其中 getLineContent 仅占不到 1%。尽管如此,我们正在考虑最终实现一个规范化步骤,如果满足某些条件(例如节点数量过多),我们将重新创建缓冲区和节点。
结论和注意事项
分块树在大多数场景下都优于行数组,除了基于行的查找,这在意料之中。
经验教训
- 这次重新实现教给我最重要的经验是**始终进行实际分析**。我每次发现我对哪些方法会很热门的假设与现实不符。例如,当我开始分块树实现时,我专注于调整三个原子操作:
insert、delete和search。但是当我将其集成到 VS Code 中时,这些优化都没有意义。最常用的方法是getLineContent。 - **处理
CRLF或混合换行符序列是程序员的噩梦**。对于每次修改,我们需要检查它是否拆分了回车/换行 (CRLF) 序列,或者是否创建了一个新的 CRLF 序列。在树的上下文中处理所有可能的情况,我尝试了几次才得到一个正确且快速的解决方案。 - **垃圾回收很容易占用你的 CPU 时间**。我们的文本模型过去假设缓冲区存储在一个数组中,我们经常使用
getLineContent,尽管有时没有必要。例如,如果我们只想知道一行第一个字符的字符代码,我们先使用getLineContent,然后执行charCodeAt。使用分块树,getLineContent会创建一个子字符串,检查字符代码后,该行子字符串会立即丢弃。这是浪费的,我们正在努力采用更合适的方法。
为什么不选择原生实现?
我在开头承诺过会回到这个问题。
**TL;DR**:我们尝试了。但对我们来说行不通。
我们用 C++ 构建了一个文本缓冲区实现,并使用原生 Node 模块绑定将其集成到 VS Code 中。文本缓冲区是 VS Code 中一个常用的组件,因此对文本缓冲区进行了许多调用。当调用方和实现都用 JavaScript 编写时,V8 能够内联许多这些调用。而使用原生文本缓冲区,存在 **JavaScript <=> C++** 的往返开销,鉴于往返次数,它们减慢了所有操作。
例如,VS Code 的“切换行注释”命令是通过遍历所有选定行并逐一分析来实现的。此逻辑是用 JavaScript 编写的,并将为每行调用 TextBuffer.getLineContent。每次调用,我们都会跨越 C++/JavaScript 边界,并且必须返回一个 JavaScript string 以遵守我们所有代码所基于的 API。
我们的选择很简单。在 C++ 中,我们可以在每次调用 getLineContent 时分配一个新的 JavaScript string,这意味着复制实际的字符串字节,或者我们利用 V8 的 SlicedString 或 ConstString 类型。然而,我们只能在底层存储也使用 V8 字符串时才能使用 V8 的字符串类型。不幸的是,V8 的字符串不是多线程安全的。
我们本可以通过更改 TextBuffer API 或将越来越多的代码转移到 C++ 以避免 JavaScript/C++ 边界成本来克服这一点。然而,我们意识到我们同时做了两件事:我们正在使用与行数组不同的数据结构编写文本缓冲区,并且我们正在用 C++ 而不是 JavaScript 编写它。因此,与其花半年时间在一些我们不知道是否会有回报的事情上,我们决定将文本缓冲区的运行时保留在 JavaScript 中,只更改数据结构和相关算法。在我们看来,这是正确的决定。
未来工作
我们仍然有一些需要优化的案例。例如,**查找**命令目前是逐行运行的,但它不应该这样。当只需要行子字符串时,我们还可以避免不必要的 getLineContent 调用。我们将逐步发布这些优化。即使没有这些进一步的优化,新的文本缓冲区实现也比我们以前的提供了更好的用户体验,并且现在是最新稳定版 VS Code 中的默认实现。
编码愉快!
吕鹏,VS Code 团队成员 @njukidreborn